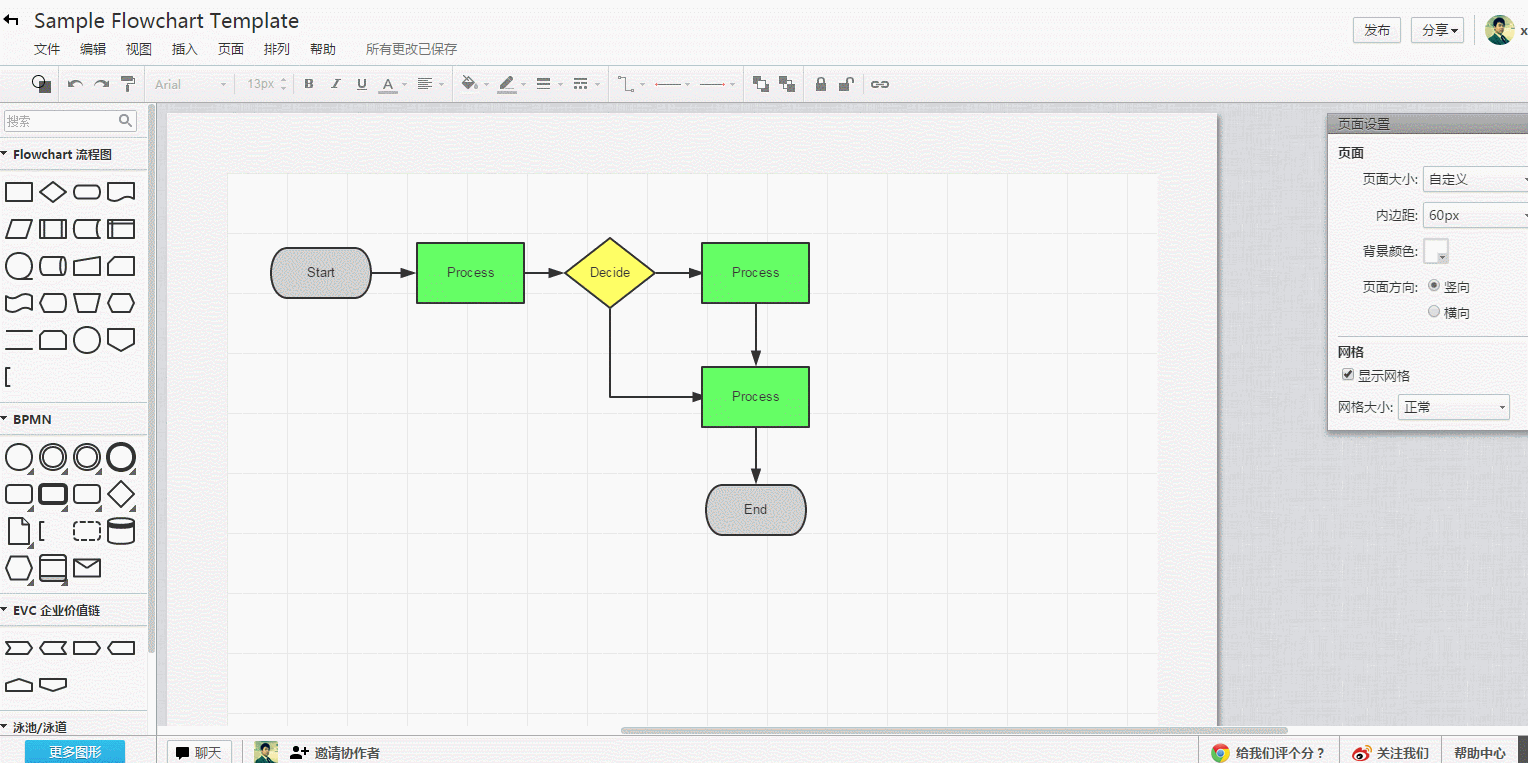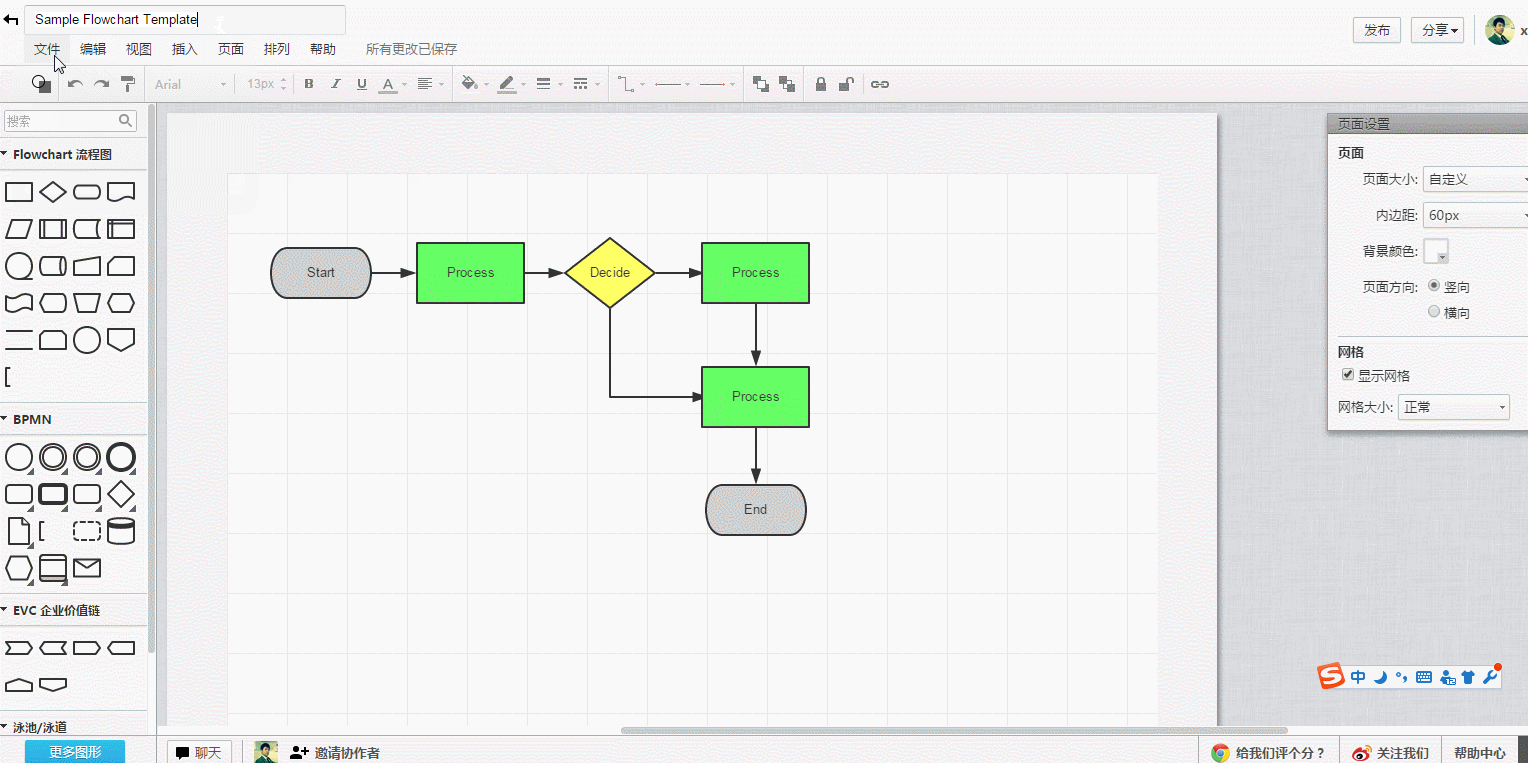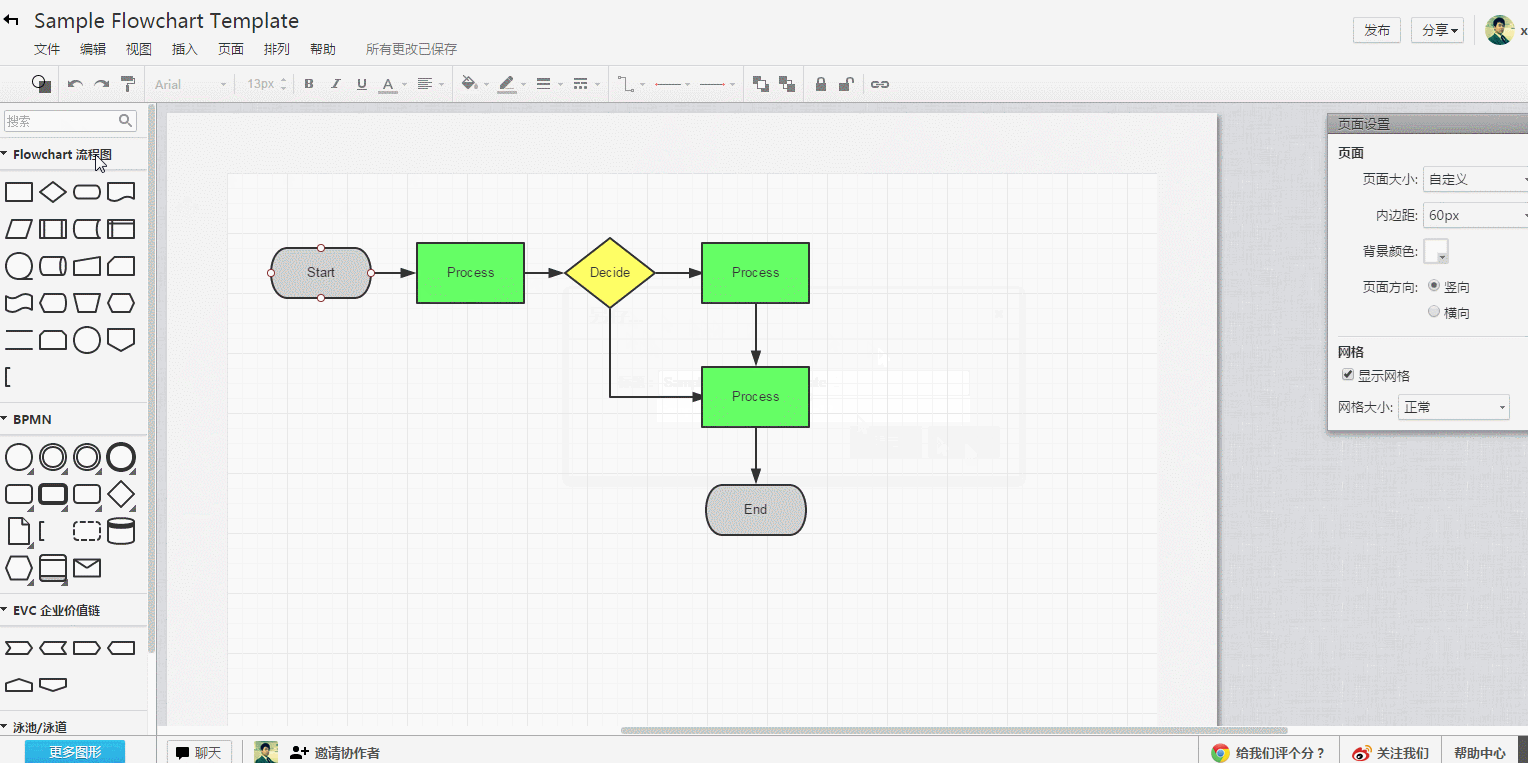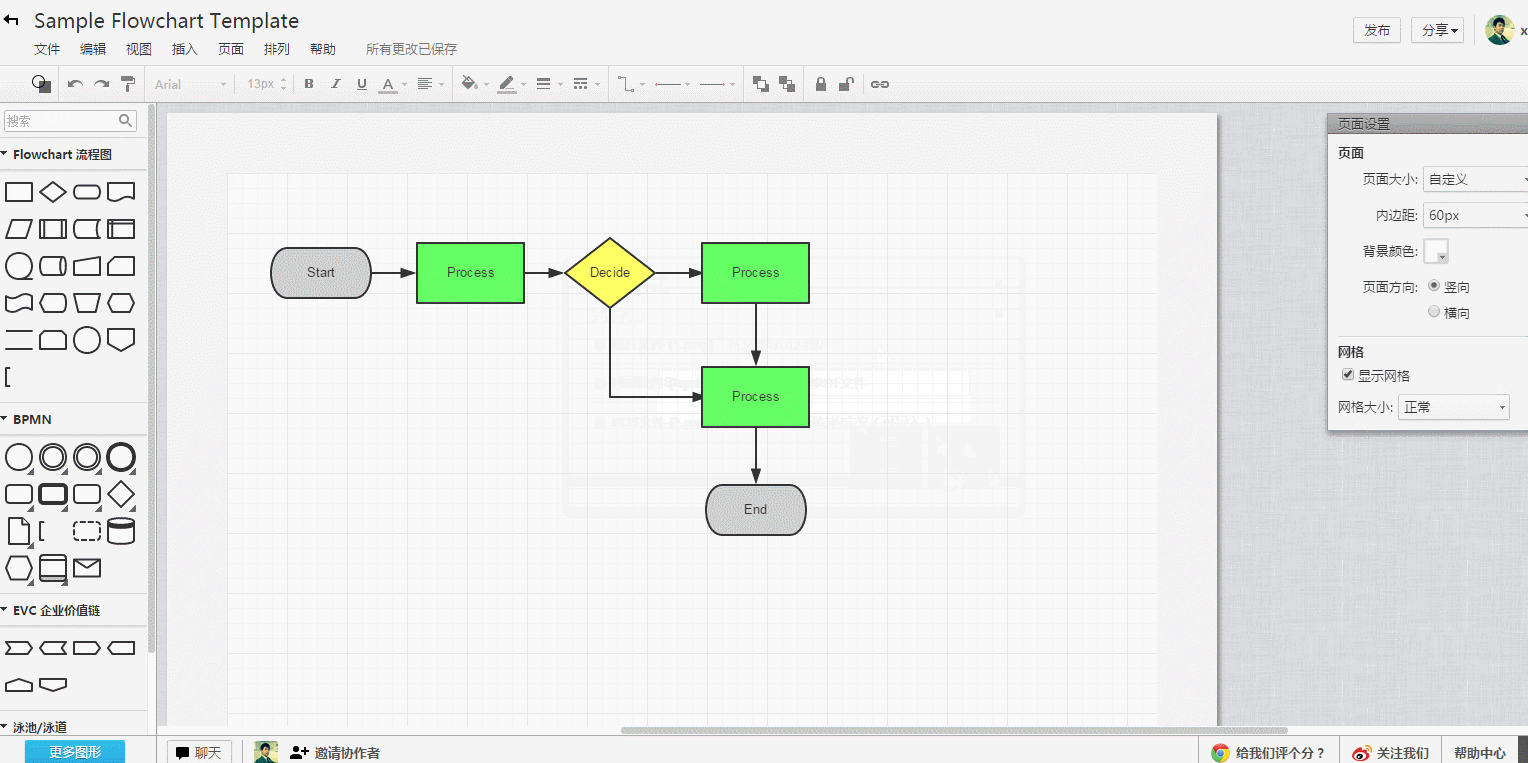
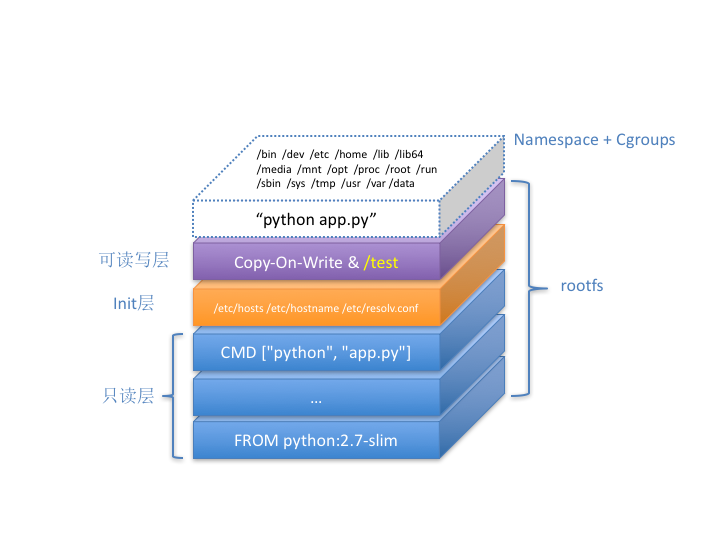
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
| # 增加network namespace ns1
[root@localhost software]# ip netns add ns1
[root@localhost software]# ip netns
ns1
# 激活namespace ns1中的lo设备
[root@localhost software]# ip netns exec ns1 ip link set dev lo up
# 创建veth pair
[root@localhost software]# ip link add veth-ns1 type veth peer name lxcbr0.1
# 多出了lxcbr0.1@veth-ns1和veth-ns1@lxcbr0.1两个设备
# 后面的操作步骤中将lxcbr0.1位于主网络命名空间中,veth-ns1位于ns1命名空间中
[root@localhost software]# ip link
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN mode DEFAULT group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
2: enp0s3: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP mode DEFAULT group default qlen 1000
link/ether 08:00:27:6c:3e:95 brd ff:ff:ff:ff:ff:ff
3: enp0s8: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP mode DEFAULT group default qlen 1000
link/ether 08:00:27:a5:78:ca brd ff:ff:ff:ff:ff:ff
4: docker0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP mode DEFAULT group default
link/ether 02:42:a3:75:00:16 brd ff:ff:ff:ff:ff:ff
18: veth71f2650@if17: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue master docker0 state UP mode DEFAULT group default
link/ether ca:05:f7:db:6f:4c brd ff:ff:ff:ff:ff:ff link-netnsid 0
19: lxcbr0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UNKNOWN mode DEFAULT group default qlen 1000
link/ether c6:b7:4d:7f:f8:90 brd ff:ff:ff:ff:ff:ff
20: lxcbr0.1@veth-ns1: <BROADCAST,MULTICAST,M-DOWN> mtu 1500 qdisc noop state DOWN mode DEFAULT group default qlen 1000
link/ether c6:8a:26:3d:ba:de brd ff:ff:ff:ff:ff:ff
21: veth-ns1@lxcbr0.1: <BROADCAST,MULTICAST,M-DOWN> mtu 1500 qdisc noop state DOWN mode DEFAULT group default qlen 1000
link/ether f2:03:22:93:d6:f4 brd ff:ff:ff:ff:ff:ff
# 将设备veth-ns1放入到ns1命名空间中
[root@localhost software]# ip link set veth-ns1 netns ns1
# 可以看到veth-ns1设备在当前命名空间消失了
[root@localhost software]# ip link
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN mode DEFAULT group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
2: enp0s3: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP mode DEFAULT group default qlen 1000
link/ether 08:00:27:6c:3e:95 brd ff:ff:ff:ff:ff:ff
3: enp0s8: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP mode DEFAULT group default qlen 1000
link/ether 08:00:27:a5:78:ca brd ff:ff:ff:ff:ff:ff
4: docker0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP mode DEFAULT group default
link/ether 02:42:a3:75:00:16 brd ff:ff:ff:ff:ff:ff
18: veth71f2650@if17: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue master docker0 state UP mode DEFAULT group default
link/ether ca:05:f7:db:6f:4c brd ff:ff:ff:ff:ff:ff link-netnsid 0
19: lxcbr0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UNKNOWN mode DEFAULT group default qlen 1000
link/ether c6:b7:4d:7f:f8:90 brd ff:ff:ff:ff:ff:ff
20: lxcbr0.1@if21: <BROADCAST,MULTICAST> mtu 1500 qdisc noop state DOWN mode DEFAULT group default qlen 1000
link/ether c6:8a:26:3d:ba:de brd ff:ff:ff:ff:ff:ff link-netnsid 1
# 同时在命名空间ns1中看到了设备veth-ns1,同时可以看到veth-ns1设备的状态为DOWN
[root@localhost software]# ip netns exec ns1 ip link
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN mode DEFAULT group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
21: veth-ns1@if20: <BROADCAST,MULTICAST> mtu 1500 qdisc noop state DOWN mode DEFAULT group default qlen 1000
link/ether f2:03:22:93:d6:f4 brd ff:ff:ff:ff:ff:ff link-netnsid 0
# 将ns1中的veth-ns1设备更名为eth0
[root@localhost software]# ip netns exec ns1 ip link set dev veth-ns1 name eth0
[root@localhost software]# ip netns exec ns1 ip link
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN mode DEFAULT group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
21: eth0@if20: <BROADCAST,MULTICAST> mtu 1500 qdisc noop state DOWN mode DEFAULT group default qlen 1000
link/ether f2:03:22:93:d6:f4 brd ff:ff:ff:ff:ff:ff link-netnsid 0
# 为容器中的网卡分配一个IP地址,并激活它
[root@localhost software]# ip netns exec ns1 ifconfig eth0 192.168.10.11/24 up
# 可以看到eth0网卡上有ip地址
[root@localhost software]# ip netns exec ns1 ifconfig
eth0: flags=4099<UP,BROADCAST,MULTICAST> mtu 1500
inet 192.168.10.11 netmask 255.255.255.0 broadcast 192.168.10.255
ether f2:03:22:93:d6:f4 txqueuelen 1000 (Ethernet)
RX packets 0 bytes 0 (0.0 B)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 0 bytes 0 (0.0 B)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
lo: flags=73<UP,LOOPBACK,RUNNING> mtu 65536
inet 127.0.0.1 netmask 255.0.0.0
inet6 ::1 prefixlen 128 scopeid 0x10<host>
loop txqueuelen 1000 (Local Loopback)
RX packets 0 bytes 0 (0.0 B)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 0 bytes 0 (0.0 B)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
# 添加一个网桥lxcbr0,类似于docker中的docker0
[root@localhost software]# brctl addbr lxcbr0
[root@localhost software]# brctl show
bridge name bridge id STP enabled interfaces
docker0 8000.0242a3750016 no veth71f2650
lxcbr0 8000.000000000000 no
# 关闭生成树协议,默认该协议为关闭状态
[root@localhost software]# brctl stp lxcbr0 off
[root@localhost software]# brctl show
bridge name bridge id STP enabled interfaces
docker0 8000.0242a3750016 no veth71f2650
lxcbr0 8000.000000000000 no
# 为网桥配置ip地址
ifconfig lxcbr0 192.168.10.1/24 up
[root@localhost software]# ifconfig lxcbr0
lxcbr0: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500
inet 192.168.10.1 netmask 255.255.255.0 broadcast 192.168.10.255
inet6 fe80::c4b7:4dff:fe7f:f890 prefixlen 64 scopeid 0x20<link>
ether c6:b7:4d:7f:f8:90 txqueuelen 1000 (Ethernet)
RX packets 0 bytes 0 (0.0 B)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 8 bytes 648 (648.0 B)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
# 将veth设备中的其中一个lxcbr0.1添加到网桥lxcbr0上
[root@localhost software]# brctl addif lxcbr0 lxcbr0.1
# 可以看到网桥lxcbr0中已经包含了设备lxcbr0.1
[root@localhost software]# brctl show
bridge name bridge id STP enabled interfaces
docker0 8000.0242a3750016 no veth71f2650
lxcbr0 8000.c68a263dbade no lxcbr0.1
# 为网络空间ns1增加默认路由规则,出口为网桥ip地址
[root@localhost software]# ip netns exec ns1 ip route add default via 192.168.10.1
[root@localhost software]# ip netns exec ns1 ip route
default via 192.168.10.1 dev eth0
192.168.10.0/24 dev eth0 proto kernel scope link src 192.168.10.11
# 为ns1增加resolv.conf
[root@localhost software]# mkdir -p /etc/netns/ns1
[root@localhost software]# echo "nameserver 8.8.8.8" > /etc/netns/ns1/resolv.conf
|