// noCopy may be embedded into structs which must not be copied // after the first use. // // See https://github.com/golang/go/issues/8005#issuecomment-190753527 // for details. type noCopy struct{}
// Lock is a no-op used by -copylocks checker from `go vet`. func(*noCopy) Lock() {}
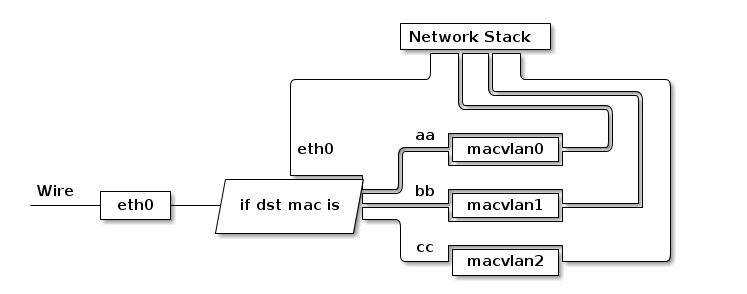
# 将mac1放入到net1 namespace中 [root@localhost vagrant]# ip link set mac1 netns net1 [root@localhost vagrant]# ip netns exec net1 ip link 1: lo: <LOOPBACK> mtu 65536 qdisc noop state DOWN mode DEFAULT link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00 24: mac1@if3: <BROADCAST,MULTICAST> mtu 1500 qdisc noop state DOWN mode DEFAULT link/ether 3e:b8:e9:1d:3b:c8 brd ff:ff:ff:ff:ff:ff link-netnsid 0
# 在net1中将mac1接口命名为eth0 [root@localhost vagrant]# ip netns exec net1 ip link set mac1 name eth0 [root@localhost vagrant]# ip netns exec net1 ip link 1: lo: <LOOPBACK> mtu 65536 qdisc noop state DOWN mode DEFAULT link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00 24: eth0@if3: <BROADCAST,MULTICAST> mtu 1500 qdisc noop state DOWN mode DEFAULT link/ether 3e:b8:e9:1d:3b:c8 brd ff:ff:ff:ff:ff:ff link-netnsid 0
# 在net1中分配eth0网卡的ip地址为192.168.8.120 [root@localhost vagrant]# ip netns exec net1 ip addr add 192.168.8.120/24 dev eth0 [root@localhost vagrant]# ip netns exec net1 ip link set eth0 up [root@localhost vagrant]# ip netns exec net1 ip link 1: lo: <LOOPBACK> mtu 65536 qdisc noop state DOWN mode DEFAULT link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00 24: eth0@if3: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UNKNOWN mode DEFAULT link/ether 3e:b8:e9:1d:3b:c8 brd ff:ff:ff:ff:ff:ff link-netnsid 0
[root@localhost vagrant]# docker network ls NETWORK ID NAME DRIVER SCOPE b6a128f1730e bridge bridge local a65957cd6c3f docker_gwbridge bridge local 540bb390028a host host local b3e83aa45886 isolated_nw bridge local ec6c4e77321d local_alias bridge local 5c637798d559 mcv macvlan local 3d247d0414d0 none null local
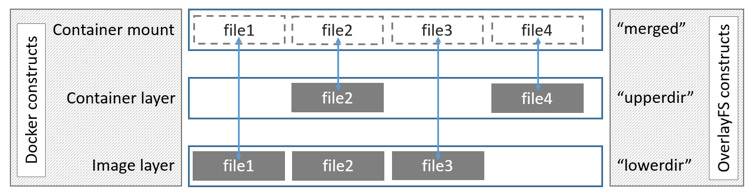
[root@localhost overlay2]# mount | grep overlay2 /dev/mapper/centos-root on /var/lib/docker/overlay2 type xfs (rw,relatime,attr2,inode64,noquota) overlay on /var/lib/docker/overlay2/0326c1da0af912a6ea5efda77b65b04e796993e0f111ed8f262c55b2716f1c08/merged type overlay (rw,relatime,lowerdir=/var/lib/docker/overlay2/l/ZJVMGTB2IOJ6QF57TYM5O7EWXW:/var/lib/docker/overlay2/l/QMKHIPSDT4JTPE4FLT7QGJ33ND:/var/lib/docker/overlay2/l/5PHT7S3MCZTTQOXVPA4CKJRRFD:/var/lib/docker/overlay2/l/HXATFASQ4E2JBG434DUEN54EZZ:/var/lib/docker/overlay2/l/WUZC5WSTQTPJUJ4KFAYCUT5IPD:/var/lib/docker/overlay2/l/MZUEUOFHBNVTRCJYJEG7QY4VWT,upperdir=/var/lib/docker/overlay2/0326c1da0af912a6ea5efda77b65b04e796993e0f111ed8f262c55b2716f1c08/diff,workdir=/var/lib/docker/overlay2/0326c1da0af912a6ea5efda77b65b04e796993e0f111ed8f262c55b2716f1c08/work)
func main() { runtime.GOMAXPROCS(1) arr := [10000]int{} for i:=0; i<len(arr); i++ { arr[i] = i } for _, a := range arr { go func() { fmt.Println(a) }() } for { time.Sleep(time.Second) } }
# Gitment # Introduction: https://imsun.net/posts/gitment-introduction/ gitment: enable: true mint: true # RECOMMEND, A mint on Gitment, to support count, language and proxy_gateway count: true # Show comments count in post meta area lazy: false # Comments lazy loading with a button cleanly: false # Hide 'Powered by ...' on footer, and more language: # Force language, or auto switch by theme github_user: kuring # MUST HAVE, Your Github ID github_repo: gitment-comments # MUST HAVE, The repo you use to store Gitment comments client_id: xxx # MUST HAVE, Github client id for the Gitment client_secret: xxxx # EITHER this or proxy_gateway, Github access secret token for the Gitment proxy_gateway: # Address of api proxy, See: https://github.com/aimingoo/intersect redirect_protocol: # Protocol of redirect_uri with force_redirect_protocol when mint enabled
执行hexo clean && hexo g && hexo s重新生成页面并在本地运行,可以看到gitment组件已经可以显示了,但是提示Error: Comments Not Initialized错误,点击login,然后允许认证,即可消除该错误。