SolrCloud官方文档翻译
本文是翻译的solrcloud的官方英文文档,本文仅将文中重点翻译,原文地址点这里。英文水平不咋地,翻译篇文章也算练练手。

SolrCloud
SolrCloud是Solr的分布式集群。可以通过集群来搭建一个高可用性,容错性的Solr服务。当想搭建一个大规模,容错性,分布式索引,查询性能好的Solr服务时可以采用SolrCloud。
关于SolrCores和Collections的一点小知识
在单机运行时,单独的索引叫做SolrCore。如果想要创建多个索引,可以创建多个SolrCore。利用SolrCloud,一个索引可以存放在不同的Solr服务上。意味着一个单独的索引可以由不同的机器上的SolrCore组成。不同机器上的SolrCore组成了逻辑上的索引,这些SolrCore叫做collection。组成collection的SolrCore包括了数据索引和备份。
例子A: 简单两个shard集群

这个例子简单创建了包含两个solr服务的集群,一个collection的数据分布到两个不同的shard上。
因为在这个例子中我们需要两个服务器,这里仅简单的复制example的数据作为第二个服务器,复制example目录之前需要确保里面没有索引数据。
1 | rm -r example/solr/collection1/data/* |
下面的命令会启动一个solr服务并启动一个新的solr集群。
1 | cd example |
-DzkRun参数会在solr服务中启动一个内置的zookeeper服务。-Dbootstrap_confdir=./solr/collection1/conf因为在zookeeper中没有solr配置信息,这一参数会将本地的./solr/conf目录下的配置信息上传到zookeeper中作为myconf配置参数。myconf是在下面的collection.configName参数中指定的。-Dcollection.configName=myconf为新的collection设置配置名称。如果不加这个参数配置默认名称为configuration1。-DnumShards=2划分索引到逻辑分区的个数。
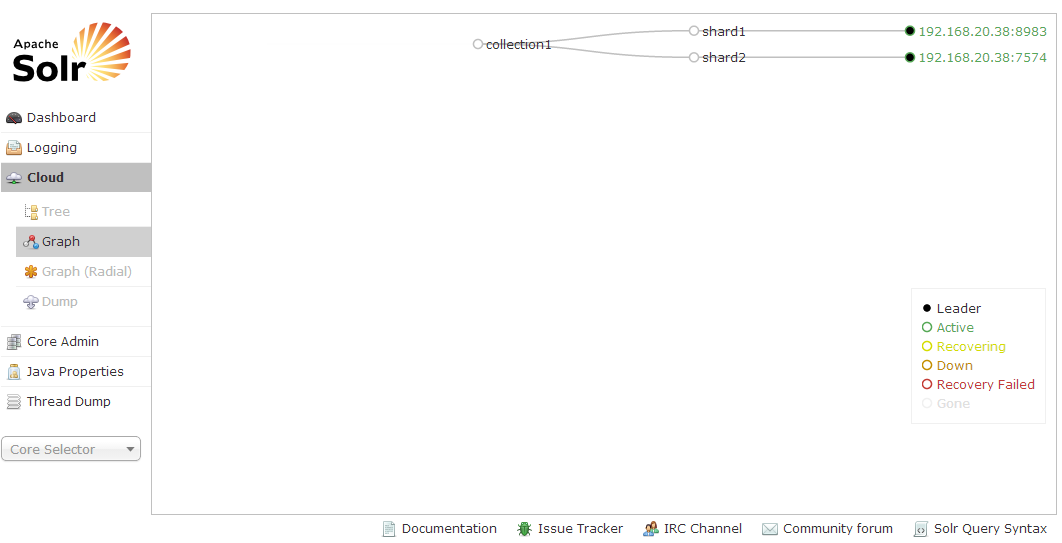
浏览http://localhost(本地主机):8983/solr/#/~cloud可以看到集群的状态。
通过目录树可以看到配置文件已经上传到了/configs/myconf/目录下,一个叫collection1的collection已经创建,在collection1下是shard的列表,这些shard组成了完整的collection。
接下来准备启动第二个服务器,因为没有明确的设置shard的id,该服务会自动分配到shard2。
启动第二个服务,并将其指向集群。
1 | cd example2 |
-Djetty.port=7574来指定Jetty的端口号。-DzkHost=localhost:9983用来指定Zookeeper集群。在本例中,在第一个Solr服务中运行了一个单独的Zookeeper服务。默认情况下,Zookeeper的端口号为Solr服务的端口号加上1000,即9983。
通过访问http://localhost(本地主机):8983/solr/#/~cloud,在collection1中就可以看到shard1和shard2。
下面对一些文档建立索引。
1 | cd exampledocs |
无论是向集群中的任何一台服务器请求都会得到全部的collection:http://localhost:8983/solr/collection1/select?q=*:*。
假如想更改配置,可以在关闭所有服务之后删除solr/zoo_data目录下的所有内容。
实际测试插入速度要比单个服务慢。
例子B:简单的两个shard重复的shard集群

本例子会通过复制shard1和shard2来创建上一个例子。额外的shard备份可以有高可用性和容错性,简单提升索引的查询能力。
首先,在运行先前的例子中我们已经有了两个shard和一些索引文档。然后简单的复制这两个服务:
1 | cp -r example exampleB |
然后,在不同的端口上启动两个新的服务:
1 | cd exampleB |
1 | cd example2B |
重新浏览网址http://localhost(本地主机):8983/solr/#/~cloud,检查四个solr节点是否已经都启动。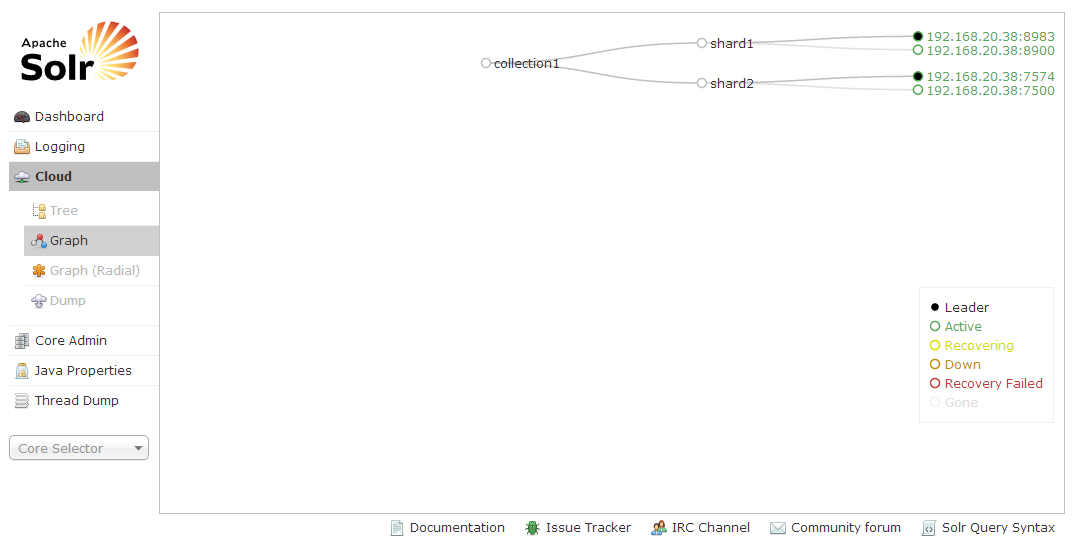
因为我们已经告诉Solr我们需要两个逻辑上的shard,启动后的实例3和4会自动的成为原来shard的备份。
向集群中的任意一个服务发起查询:http://localhost:7500/solr/collection1/select?q=*:*。多次发起这个查询并查看solr服务的日志。可以观察到Solr通过备份对请求做了平衡,通过不同的服务来处理请求。
为了证明高可用性,在除了运行Zookeeper的服务上按下CTRL-C。(在例子C中将会讨论Zookeeper的冗余)当服务终止后,发送另外一个查询请求到其他服务,仍然能够看到所有的结果。
在没一个shard至少还有一个服务时,SolrCloud仍然可以提供服务。可以通过关闭每一个实例来查看结果。假如关闭了一个shard的所有的服务,到其他服务的请求就会收到503错误。为了能够返回其他可用的shard中的文档,可以在请求中增加参数:shards.tolerant=true。
SolrCloud用leaders和overseer来作为具体的实现。一些节点或备份将会扮演特殊的角色。不需要担心杀死了leader或overseer,假如杀死了其中的一个,集群会自动选择一个新的leader或overseer,并自动接管工作。任何的Solr实例都可以成为这种角色。
例子C:两个shard集群,shard带备份和zookeeper集群

在例子B中问题是虽然有足够的Solr服务器可以避免集群挂掉,但是仅有一个zookeeper服务来维持集群的状态。假如zookeeper服务挂掉了,分布式的查询还是可以工作的,因为solr服务记录了zookeeper最后一次报告的状态。问题是没有新的服务器或客户端能发现集群的状态,集群的状态也不会改变。
运行多个zookeeper服务可以保证zookeeper服务具有高可用性。每一个zookeeper服务需要知道集群中的其他服务,大部分服务需要提供服务。例如,一个含有三个zookeeper服务的集群允许其中一个失败剩余的两个仍然可以提供服务。五个zookeeper服务的集群可以允许一次失败两个。
从产品角度考虑,推荐使用单独的zookeeper服务而不是solr服务中集成的zookeeper服务。你可以从这里读取到更多的zookeeper集群。在这个简单的例子中,我们仅简单的使用了集成的zookeeper。
首先,停止四个服务,并清空zookeeper中的数据作为一个新的开始。
1 | rm -r example*/solr/zoo_data |
我们仍然将服务分别运行在8983,7574,8900,7500端口。默认是在端口号+1000的端口上启动一个zookeeper服务,第一次运行的时候在另外三台服务器上zookeeper的地址分别为:localhost:9983,localhost:8574,localhost:9900。
为了方便通过第一个服务上传solr的配置到zookeeper集群中。在第二个zookeeper服务启动之前程序会阻塞。这是因为zookeeper在工作的时候需要其他服务。
1 | cd example |
1 | cd example2 |
1 | cd exampleB |
1 | cd example2B |
现在我们运行了三个内置的zookeeper服务,如果一个服务挂掉之后其他一切正常。为了证明,在exampleB上按下CTRL+C杀掉服务,然后浏览http://localhost:8983/solr/#/~cloud来核实zookeeper服务仍然可以工作。
需要注意的是,当运行在多个机器上,需要在每一台机器上设置-DzkRun=hostname:port属性。
ZooKeeper
多个zookeeper服务同时运行来避免错误和高可用性叫做ensemble。从产品角度,推荐运行外部的zookeeper ensemble来代替solr集成的zookeeper。浏览zookeeper官方网站下载和运行一个zookeeper ensemble。可以参考Getting Started和ZooKeeper Admin。非常简单就可以运行。可以坚持使用solr来运行zookeeper集群,但是必须知道zookeeper集群不是非常容易动态改变的。除非solr增加对zookeeper更好的支持,重新开始是最好的改变方式。zookeeper和solr是两个不同的进程是最好的方式。
当solr运行内置的zookeeper服务时,默认会使用solr服务的端口号加上1000作为zookeeper的客户端端口号。另外,默认会增加一个zookeeper的客户端端口号和两个zookeeper的选举端口号。所以在第一个例子中,solr运行在8983端口,内置的zookeeper服务运行在9983端口作为客户端端口,9984和9985作为服务端端口。
当增加了更多zookeeper节点可以提高读性能,但是会稍微降低写性能。当集群状态稳定的时候,Solr用的Zookeeper非常少。下面有一些优化zookeeper的建议:
- 最好的情况是zookeeper有一个专用的机器。zookeeper是一个准时的服务,专用的机器可以确保及时响应。当然专用的机器不是必须的。
- 当把事务日志和snap-shots放到不同的磁盘上可以提高性能。
- 假如zookeeper和solr运行在同一台机器上,利用不同的磁盘可以提高性能。