语言模型雏形 - 词袋模型
本文为对《GPT 图解 - 大模型是怎样构建的》一书的学习笔记,所有的例子和代码均来源于本书。
基本介绍
Bag-of-Words 模型为早期的语言模型,诞生于 1954 年。
核心思想:将文本中的词看作一个个独立的个体,不考虑在句子中的顺序,只关心词出现频次。
应用场景:文本分析、情感分析
代码实践
准备数据集
1 | corpus = ["我特别特别喜欢看电影", |
对数据集进行分词
1 | import jieba |
分词完成的结果如下:
1 | [['我', '特别', '特别', '喜欢', '看', '电影'], ['这部', '电影', '真的', '是', '很', '好看', '的', '电影'], ['今天天气', '真好', '是', '难得', '的', '好', '天气'], ['我', '今天', '去', '看', '了', '一部', '电影'], ['电影院', '的', '电影', '都', '很', '好看']] |
创建词汇表
1 | word_dict = {} # 初始化词汇表 |
获取到如下结果,其中 key 为对应的词,value 为词出现的频率。
1 | 词汇表: {'我': 0, '特别': 1, '喜欢': 2, '看': 3, '电影': 4, '这部': 5, '真的': 6, '是': 7, '很': 8, '好看': 9, '的': 10, '今天天气': 11, '真好': 12, '难得': 13, '好': 14, '天气': 15, '今天': 16, '去': 17, '了': 18, '一部': 19, '电影院': 20, '都': 21} |
生成词袋表示
1 | # 根据词汇表将句子转换为词袋表示 |
输出如下结果:
1 | [ |
输出结果需要稍微理解一下
- 数组中的每一行表示语料中的一句话
- 每个元素表示该词在当前句子中出现的次数。例如第一行的第二个元素 2 为“特别”,说明“特别”在第一句话“我特别特别喜欢看电影”总一共出现了两次。
- 每一行一共有 22 个元素,说明所有的语料一共有 22 个词。
可以看到整个的输出结果为一个稀疏矩阵,尤其是当词汇量变大后,矩阵会更加稀疏。
计算余弦相似度
该步骤需要有一点数学基础。
余弦相似度:用来衡量两个向量的相似程度。值在 -1 到 1 之间,值越接近 1,两个向量越相似。越接近 -1,表示两个向量越不相似。值为 0 时,表示没有明显的相似性。
公式如下:
1 | (A * B) / (||A|| * ||B||) |
(A * B) 为向量的点积,||A|| 和 ||B|| 表示向量的长度。
1 | # 导入 numpy 库,用于计算余弦相似度 |
可视化余弦相似度
1 | # 导入 matplotlib 库,用于可视化余弦相似度矩阵 |
最终获取到如下的结果: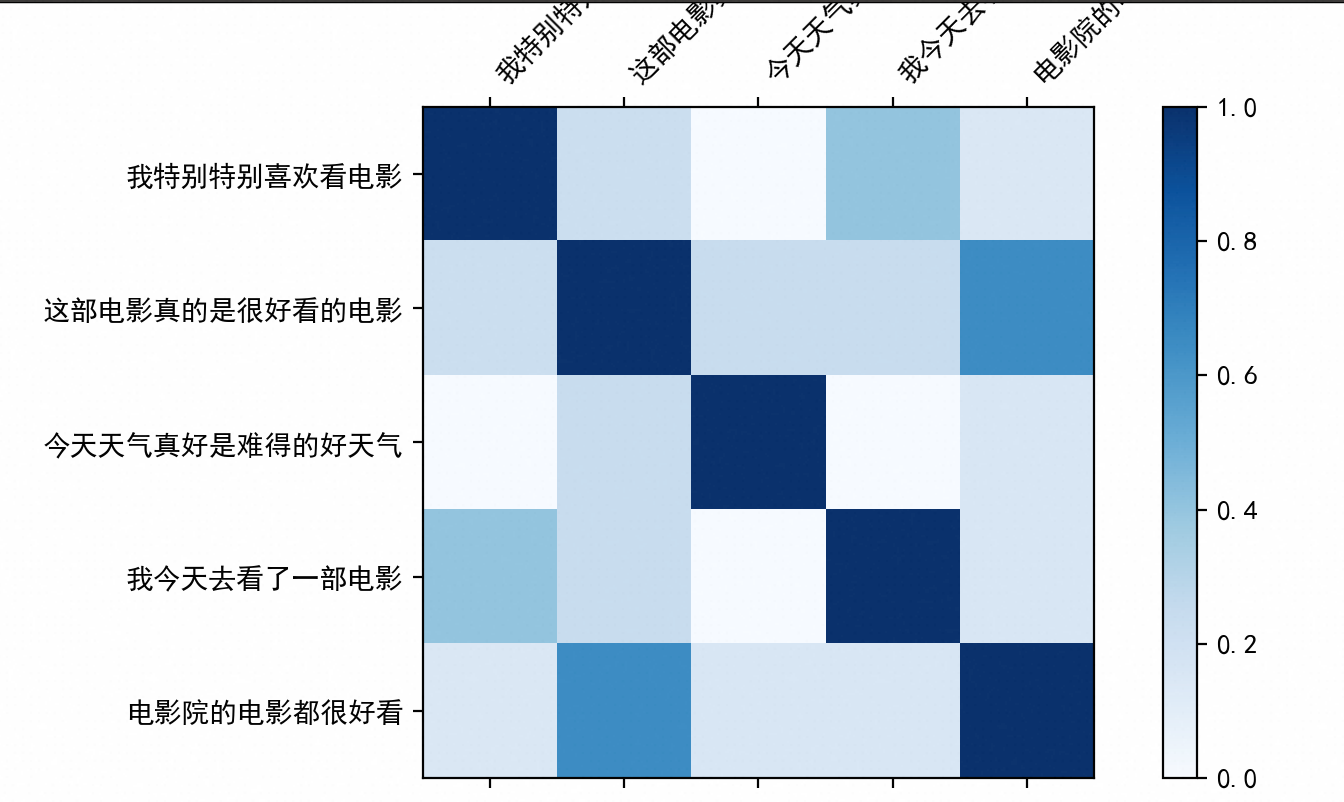
每个单元格表示两个句子之间的相似度。
总结
缺点:
- 采用了稀疏矩阵,每个单词是一个维度,计算效率较低。
- 忽略了文本的上下文信息。