术语
host cluster:virtual cluster 中的宿主 k8s 集群,承载了所有的计算资源。也会被叫做 super cluster。
virtual cluster:virtual cluster 中的租户 k8s 集群,通常简写 vc。也会被叫做 tenant cluster。
vCluster:k8s virtual cluster 的实现之一,即本文中要介绍的方案。
项目简介 k8s 的多租功能
使用全局对象存在冲突,比如 CRD。
存在诸多安全性问题,比如多个租户之间的 pod 完全可以互访,没有任何隔离机制。
不同组件对于 k8s 的版本不统一。
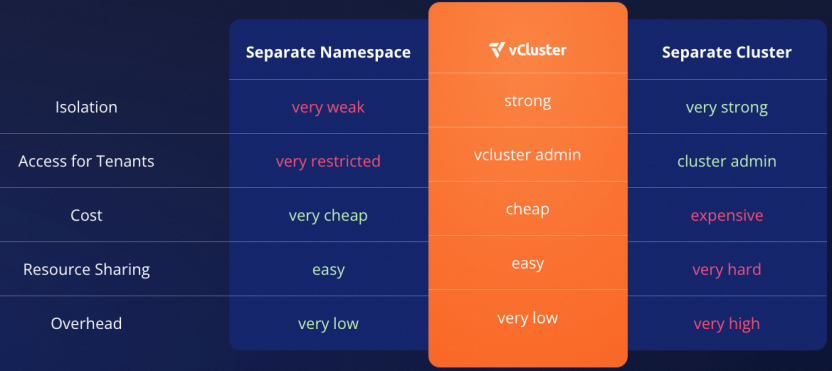
为了解决多租的问题,最简单的思路就是使用多 k8s 集群,业界的 KubeFed v2、karmada、clusternet、OCM 等均为多 k8s 集群的实现。但多 k8s 集群因为存在独立的控制面和计算资源,存在资源消耗过多的问题。
还有一个中间思路为仅做 k8s 的控制面隔离,计算资源仍然共享,即 pod 也可以解决很多的多租隔离问题。k8s 的控制面隔离又存在两个主要方案:
独立的 kube-apiserver 和 etcd、kube-controller-manager, kube-scheduler 共享 host cluster。该方案中有独立的 kube-apiserver 组件,这里的 etcd 可以被 sqllite、mysql 等存储取代。该方案统称为 virtual cluster,简称为 vc。
独立的 proxy apiserver,kube-apiserver、kube-controller-manager、kube-scheduler 共享 host cluster。访问 k8s 的请求先到 proxy apiserver,proxy apiserver 转发到 host cluster 的 kube-apiserver。可以在 proxy apiserver 中提供独立的 RBAC 机制,实现一定程度的隔离。该方案在开源中未看到具体的实现。
vCluster 介绍 vCluster 为 virtual cluster 的开源实现之一,由 Loft Labs 提供,Github Star 3.7K,代码行数 4 万行。除了开源版本外,还提供了商业版本 vCluster PRO。
vCluster 设计原则:
最小化资源占用。在实现上使用了单 pod 的 k3s 作为 k8s 的控制面。
复用 host cluster 的计算、存储和网络资源。
降低对 host cluster 的请求。
简单灵活。
不需要 host cluster 的管理员权限。
vCluster 多个 namespace 下的对象映射到 host cluster 的同一个 namespace 下。同时也可以支持 vCluster 的一个 namespace 对应 host cluster 的一个 namespace。
易清理。
Getting Started k8s 集群准备 k8s 集群这里使用了 kind 方案,kind 配置 kind.conf 如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 kind: Cluster apiVersion: kind.x-k8s.io/v1alpha4 name: vcluster nodes: - role: control-plane kubeadmConfigPatches: - | kind: InitConfiguration nodeRegistration: kubeletExtraArgs: node-labels: "ingress-ready=true" extraPortMappings: - containerPort: 80 hostPort: 80 protocol: TCP - containerPort: 443 hostPort: 443 protocol: TCP - role: worker - role: worker - role: worker networking: apiServerPort: 6443
执行 kind create cluster --config kind.conf 即可创建 k8s 集群,包含了一个 control-plane 节点,三个 worker 节点。
安装 vcluster vCluster 提供了使用 vcluster cli、helm 和 kubectl 三种安装方式,使用 vcluster cli 最为简单,其底层同样采用 helm chart 的方式部署,下面采用 vcluster cli 的方式进行安装。
1 curl -L -o vcluster "https://github.com/loft-sh/vcluster/releases/latest/download/vcluster-darwin-arm64" && sudo install -c -m 0755 vcluster /usr/local/bin && rm -f vcluster
或者执行 brew install vcluster安装 vcluster 命令行工具。
执行命令 vcluster create my-vcluster 创建 virtual cluster。会在 host cluster 上创建 namespace vcluster-my-vcluster,该 namespace 下创建如下对象:
1 2 3 4 5 6 7 8 9 10 11 12 13 $ kubectl get all -n vcluster-my-vcluster NAME READY STATUS RESTARTS AGE pod/coredns-68559449b6-l5whx-x-kube-system-x-my-vcluster 1 /1 Running 2 (5m45s ago) 3d pod/my-vcluster-0 1 /1 Running 2 (5m45s ago) 3d NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE service/kube-dns-x-kube-system-x-my-vcluster ClusterIP 10.96 .67 .119 <none> 53 /UDP,53/TCP,9153/TCP 3d service/my-vcluster NodePort 10.96 .214 .58 <none> 443 :30540/TCP,10250:31621/TCP 3d service/my-vcluster-headless ClusterIP None <none> 443 /TCP 3d service/my-vcluster-node-vcluster-control-plane ClusterIP 10.96 .69 .115 <none> 10250 /TCP 3d NAME READY AGE statefulset.apps/my-vcluster 1 /1 3d
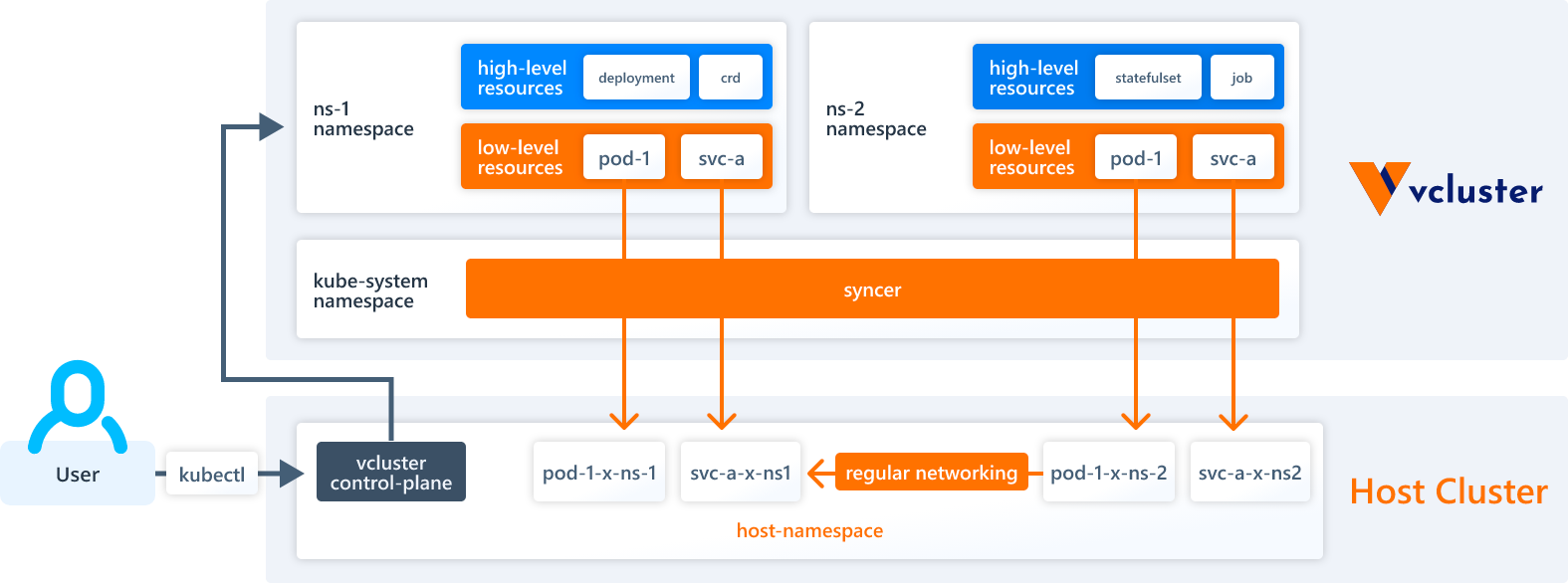
可以看到在该 namespace 下创建了 coredns 和 StatefulSet my-vcluster。每个租户有独立的 coredns 组件,用来做域名解析。my-vcluster 为 vCluster 的管控面组件,包括了 k8s controller plane 和 syncer 组件。
执行 vcluster connect my-vcluster 后会在本地启动代理,并自动切换本地的 kubeconfig context,将 context 切换到 virtual cluster。执行 kubectl 命令即可连接到对应的 k8s 集群。virtual cluster 集群中的信息如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 $ kubectl get all -A NAMESPACE NAME READY STATUS RESTARTS AGE kube-system pod/coredns-68559449b6-jg2bs 1 /1 Running 1 (20m ago) 51m NAMESPACE NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE kube-system service/kube-dns ClusterIP 10.96 .120 .59 <none> 53 /UDP,53/TCP,9153/TCP 51m default service/kubernetes ClusterIP 10.96 .35 .53 <none> 443 /TCP 51m NAMESPACE NAME READY UP-TO-DATE AVAILABLE AGE kube-system deployment.apps/coredns 1 /1 1 1 51m NAMESPACE NAME DESIRED CURRENT READY AGE kube-system replicaset.apps/coredns-68559449b6 1 1 1 51m
在 virtual cluster 可以看到仅包含了 coredns 组件。
在 virtual cluster 和在 host cluster 中的 node 信息:
1 2 3 4 5 6 7 8 9 10 $ kubectl get node -o wide NAME STATUS ROLES AGE VERSION INTERNAL-IP EXTERNAL-IP OS-IMAGE KERNEL-VERSION CONTAINER-RUNTIME vcluster-worker3 Ready <none> 51m v1.27.3 10.96 .118 .228 <none> Debian GNU/Linux 11 (bullseye) 5.10 .76 -linuxkit containerd://1.7.1 $ kubectl get node -o wide --context kind-vcluster NAME STATUS ROLES AGE VERSION INTERNAL-IP EXTERNAL-IP OS-IMAGE KERNEL-VERSION CONTAINER-RUNTIME vcluster-control-plane Ready control-plane 86m v1.27.3 172.19 .0 .3 <none> Debian GNU/Linux 11 (bullseye) 5.10 .76 -linuxkit containerd://1.7.1 vcluster-worker Ready <none> 85m v1.27.3 172.19 .0 .2 <none> Debian GNU/Linux 11 (bullseye) 5.10 .76 -linuxkit containerd://1.7.1 vcluster-worker2 Ready <none> 85m v1.27.3 172.19 .0 .5 <none> Debian GNU/Linux 11 (bullseye) 5.10 .76 -linuxkit containerd://1.7.1 vcluster-worker3 Ready <none> 85m v1.27.3 172.19 .0 .4 <none> Debian GNU/Linux 11 (bullseye) 5.10 .76 -linuxkit containerd://1.7.1
可以看到在 virtual cluster 和 host cluster 中的 node 名字相同,这是因为 node 在 vCluster 中并没有做隔离,而是从 host cluster 中做了同步。但 virtual cluster 中的 node 节点仅包含 pod 在 host cluster 中已经使用的 node 节点,未使用的节点并不会在 virtual cluster 上。$vClusterName-node-$hostClusterNodeName。
1 2 3 $ kubectl get svc --context kind-vcluster -n vcluster-my-vcluster my-vcluster-node-vcluster-worker3 NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE my-vcluster-node-vcluster-worker3 ClusterIP 10.96 .118 .228 <none> 10250 /TCP 3h54m
在 virtual cluster 中创建 k8s 对象:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 $ kubectl create ns demo-nginx namespace/demo-nginx created $ kubectl create deployment nginx-deployment -n demo-nginx --image=nginx $ kubectl get pod -n demo-nginx -o wide NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES nginx-deployment-66fb7f764c-dn59g 1 /1 Running 0 11m 10.244 .0 .7 vcluster-control-plane <none> <none> $ kubectl get node NAME STATUS ROLES AGE VERSION vcluster-worker2 Ready <none> 2m45s v1.27.3 vcluster-worker3 Ready <none> 57m v1.27.3
在 host cluster 中看到如下对象:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 $ kubectl get ns --context kind-vcluster demo-nginx Error from server (NotFound): namespaces "demo-nginx" not found $ kubectl get deploy -A --context kind-vcluster NAMESPACE NAME READY UP-TO-DATE AVAILABLE AGE ingress-nginx ingress-nginx-controller 1 /1 1 1 90m kube-system coredns 2 /2 2 2 91m local-path-storage local-path-provisioner 1 /1 1 1 91m $ kubectl get pod -n vcluster-my-vcluster --context kind-vcluster NAME READY STATUS RESTARTS AGE coredns-68559449b6-jg2bs-x-kube-system-x-my-vcluster 1 /1 Running 1 (26m ago) 57m my-vcluster-0 1 /1 Running 1 (26m ago) 86m nginx-deployment-66fb7f764c-sffqt-x-demo-nginx-x-my-vcluster 1 /1 Running 0 2m22s
可以看到仅 pod 在 host cluster 中同步存在,而 namespace、deployment 这些对象仅存在于 virtual cluster 中。在 virtual cluster 中创建的多个不同 namespace pod 仅会存在于 host cluster 的同一个 namespace 下。
验证 service 在 virtual cluster 中创建 service 对象:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 apiVersion: v1 kind: Service metadata: labels: app: nginx kubernetes.io/cluster-service: "true" name: nginx namespace: demo-nginx spec: ipFamilies: - IPv4 ipFamilyPolicy: SingleStack ports: - name: http port: 80 protocol: TCP targetPort: 80 selector: app: nginx-deployment type: ClusterIP
在 virtual cluster 中包含如下的 Service 对象:
1 2 3 $ kubectl get svc -n demo-nginx NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE nginx ClusterIP 10.96 .239 .53 <none> 80 /TCP 2m11s
在 host cluster 中会同步创建如下的 Service 对象,内容如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 apiVersion: v1 kind: Service metadata: annotations: vcluster.loft.sh/object-name: nginx vcluster.loft.sh/object-namespace: demo-nginx vcluster.loft.sh/object-uid: 5ab7aa9c-90b6-46f9-a162-9ea9ca9826f3 creationTimestamp: "2023-11-28T09:32:22Z" labels: vcluster.loft.sh/label-my-vcluster-x-a172cedcae: nginx vcluster.loft.sh/label-my-vcluster-x-d9125f8911: "true" vcluster.loft.sh/managed-by: my-vcluster vcluster.loft.sh/namespace: demo-nginx name: nginx-x-demo-nginx-x-my-vcluster namespace: vcluster-my-vcluster ownerReferences: - apiVersion: v1 controller: false kind: Service name: my-vcluster uid: 463a503e-d889-49a7-94e0-0cba5299dd47 resourceVersion: "12344" uid: fc9ea383-996e-471c-9c27-ee1c22fec7a3 spec: clusterIP: 10.96 .239 .53 clusterIPs: - 10.96 .239 .53 internalTrafficPolicy: Cluster ipFamilies: - IPv4 ipFamilyPolicy: SingleStack ports: - name: http port: 80 protocol: TCP targetPort: 80 selector: vcluster.loft.sh/label-my-vcluster-x-a172cedcae: nginx-deployment vcluster.loft.sh/managed-by: my-vcluster vcluster.loft.sh/namespace: demo-nginx sessionAffinity: None type: ClusterIP status: loadBalancer: {}
可以看到 host cluster 中的 service 的 ClusterIP 跟 virutal cluster 一致,但 spec.selector 字段已经被 syncer 修改,以便可以匹配到正确的 pod。
验证 Ingress 默认情况下 Ingress 不会同步到 host cluster,需要通过开关的方式启动。创建文件 values.yaml,内容如下:
1 2 3 sync: ingresses: enabled: true
执行 vcluster create my-vcluster --upgrade -f values.yaml 即可修改现在 vcluster 集群配置。
在 virtual cluster 中创建如下的 Ingress 对象:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 apiVersion: networking.k8s.io/v1 kind: Ingress metadata: labels: app: nginx name: nginx namespace: demo-nginx spec: rules: - host: nginx.aa.com http: paths: - backend: service: name: nginx port: number: 80 path: / pathType: ImplementationSpecific
查看 host cluster 中的 Ingress 信息如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 $ kubectl get ingress --context kind-vcluster -n vcluster-my-vcluster -o yaml nginx-x-demo-nginx-x-my-vcluster apiVersion: networking.k8s.io/v1 kind: Ingress metadata: annotations: vcluster.loft.sh/object-name: nginx vcluster.loft.sh/object-namespace: demo-nginx vcluster.loft.sh/object-uid: 4b8034a6-1513-4ccd-b80a-66807d862b4e creationTimestamp: "2023-11-28T10:07:52Z" generation: 1 labels: vcluster.loft.sh/label-my-vcluster-x-a172cedcae: nginx vcluster.loft.sh/managed-by: my-vcluster vcluster.loft.sh/namespace: demo-nginx name: nginx-x-demo-nginx-x-my-vcluster namespace: vcluster-my-vcluster ownerReferences: - apiVersion: v1 controller: false kind: Service name: my-vcluster uid: 463a503e-d889-49a7-94e0-0cba5299dd47 resourceVersion: "16292" uid: 1d0de02b-5aad-4858-a8cf-2caa345ca85b spec: rules: - host: nginx.aa.com http: paths: - backend: service: name: nginx-x-demo-nginx-x-my-vcluster port: number: 80 path: / pathType: ImplementationSpecific status: loadBalancer: ingress: - hostname: localhost
可以看到 Ingress 中对应的 Service 名字已经修改了 host cluster 中对应的 Service 名字。
销毁 在使用完成后执行如下命令即可销毁 virtual cluster:
1 2 3 4 # 切换本地的 context vcluster disconnect # 删除 vcluster vcluster delete my-vcluster
架构
组件 整个架构中,有两大核心组件:k8s Control Plane 和 syncer。其中 StatefulSet my-vcluster 中容器 syncer,默认情况下在该容器中同时启动了 k3s 容器作为 vCluster 控制平面和 vCluster 的 syncer 进程。
1 2 3 4 5 6 $ kubectl exec -it --context kind-vcluster -n vcluster-my-vcluster my-vcluster-0 -- ps -ef Defaulted container "syncer" out of: syncer, vcluster (init) PID USER TIME COMMAND 1 root 2:57 /vcluster start --name=my-vcluster --kube-config=/data/k3s 17 root 18:35 /k3s-binary/k3s server 46 root 0:00 ps -ef
controller plane 控制平面默认使用 k3s,存储使用 sqllite,也可以使用 etcd、mysql、postgresql。k8s 发行版也可以使用 k0s、Vanilla(标准 k8s)、第三方镜像等。控制平面由如下几个组件组成:
k8s apiserver。
数据存储,比如 sqllite、etcd 等。
kube-controller-manager
kube-scheduler:可选组件,默认使用 host cluster 调度器。
在 Pro 版本中,允许控制面跟 pod 部署在不同的 host cluster。
syncer virtual cluster 中并不包含实际的计算、存储和网络资源,syncer 的职责为将对象从 virtual cluster 同步到 host cluster,也有少部分对象需要从 host cluster 同步到 virtual cluster。配置的方式 来定制资源的同步,更复杂的同步规则提供了插件机制 实现。https://www.vcluster.com/docs/syncer/core_resources 。
已经创建完成的 syncer 配置,可以通过 vcluster create my-vcluster --upgrade -f values.yaml 的方式修改,该命令会调用 helm update,helm update 命令最终会修改 StatefulSet syncer 的配置,并触发 pod 的重启。
k8s node 同步 支持多种 node 的同步行为,通过修改 syncer 的启动参数:
Fake Node:默认行为。根据 pod 中的 spec.nodeName 创建 Fake Node。Fake Node 为 syncer 服务自动创建。如果没有 pod 调度到 Fake Node 上,则 Fake Node 会自动删除。
Real Node:根据 pod 中的 spec.nodeName 创建 Real Node,Real Node 的信息从 host cluster 同步。如果没有 pod 调度到 Real Node 上,则 Real Node 会自动删除。
Real Node All:同步 host cluster 的所有 node 到 virtual cluster。如果要使用 DaemonSet,需要使用该模式。
Real Nodes Label Selector:仅同步 label selector 匹配的 host node 到 virtual cluster 中。
Real Nodes + Label Selector:仅同步包含在 pod spec.nodeName 且 Label selector 可以选中的 host cluster node 到 virtual cluster 中。
pod 调度 默认情况下,virtual cluster 中的 pod 调度会使用 host cluster 的调度,但存在如下的问题:
在 virtual cluster node 上的 label 对于 pod 调度不会生效。
drait、trait 命令对于 virtual cluster 上的 pod 没有影响。
virtual cluster 中使用自定义调度器不生效。
基于上述限制,vCluster 支持如下两种方案:
支持在 virtual cluster 中使用独立的调度器。可以给 virtual cluster 上的 node 增加标签、污点等信息,pod 的调度在 virtual cluster 中的调度器实现,syncer 组件仅将已经调度完成的 pod 同步到 host cluster。
仍然复用 host cluster 调度器,但做了部分功能的增强:在 syncer 服务中指定仅同步部分 host node 到 virtual cluster 中,这样 pod 就仅会调度到 host cluster 的特定 node 上。
网络 virutal cluster 中无独立的 pod 网络和 service 网络,完全复用 host cluster 的网络。
Service 网络
会从 virtual cluster 同步到 host cluster,两者的 clusterip 一致。
允许将一些 host cluster 中的 service 同步到 virtual cluster 中,同时指定service 的名字。
允许将 virtual cluster 中的 service 同步到 host cluster 中,同时指定service 的名字。
Ingress 网络 允许将 virtual cluster 中的 Ingress 同步到 host cluster,以便复用 host cluster 中的 Ingress Controller。
DNS 解析 在 virtual cluster 中部署了单独的 coredns 组件,默认情况下,在 vritual cluster 中的域名仅能解析内部的域名,不能解析 host cluster 上的域名。可以通过开关的方式,将 virtual cluster 中的域名解析转发到 host cluster 的 coredns。
在 PRO 版本中,coredns 组件可以集成到 syncer 组件内部,以便节省资源。
NetworkPolicy 默认情况下,vcluster 中会忽略 virtual cluster 中的 NetworkPolicy 资源。可以通过开关的方式打开该配置,即可将 NetworkPolicy 规则同步到 host cluster。
存储
可观测性 monitoring metrics-server 用来监控 k8s 的 Deployment、StatefulSet 等对象,metrics-server 可以复用 host cluster 中的,但需要启用 metrics server proxy 功能。也可以在 vc 中单独部署一套 metrics server。
logging 需要用到Hostpath Mapper组件,该组件为 DaemonSet 的形式。后续即可以部署 loki 等组件。
安全 隔离模式 在启动的时候指定--isolate,在该模式下对 workload 做了多种限制。
对 vcluster pod 的 Pod Security 做限制,不符合规范的 pod 不会同步到 host cluster。
可以对 vc 中 pod 的总资源量做限制。
在 host cluster 上通过 NetworkPolicy 做隔离。
virtual cluster 集群的创建 目前仅能通过 vcluster cli、helm 的方式来创建,底层均为 helm chart 的方式来管理,缺少服务化功能。
virtual cluster 集群对外暴露方法 获取 kubeconfig vcluster connect 命令 该命令可以修改本地的 kubeconfig 文件,并将 context 切换为 virtual cluster context。默认为 virutual cluster 的管理员权限,可以指定使用特定的 ServiceAccount。
host cluster secret 中获取到 kubeconfig 在 host cluster 中,在 vc 的 namespace 下,存在一个以 vc- 开头的 Secret,该 Secret 中保存了 kubeconfig 完整信息。
vc 集群中的 apiserver 的暴露地址 可以在 syncer 启动的时候指定获取的 kubeconfig 中的 endpoint 地址。endpoint 地址即为 vc 集群中的 kube-apiserver 的地址,该 kube-apiserver 的地址可以通过 host cluster 中的 Ingress、LoadBalancer Service、NodePort Service 等方式对外暴露。
高可用设计 control plane 高可用 k3s 可以支持高可用架构,在创建 vc 的时候通过指定的副本的方式来设置高可用。其他的 k8s 发行版同样类似的实现。
备份与恢复 vCluster 本身并没有提供对于 vc 集群的数据备份与恢复功能,可以通过通用的 velero 方式实现备份与恢复功能。
总结 未做网络隔离,容器网络和 service 网络仍然在同一个平面,要想相互隔离,必须使用 NetworkPolicy。
其他
获取 helm chart 到本地
helm repo add lofts https://charts.loft.sh/
helm fetch lofts/vcluster
``