1 2 3 4 class X {}; class Y : public virtual X {}; class Z : public virtual X {}; class A : public Y, public Z {};
对于上述代码我在vs2008中的实验结果,X的大小为1,Y和Z的大小为4,A的大小为8。X的大小为1是因为编译器给空类了1字节的空间。Y和Z的大小为4是因为内部包含一个vbptr(指向虚基类的指针)占用了4个字节。A的大小包含了两个vbptr,分别指向虚基类的指针X。利用cl main.cpp /d1reportSingleClassLayoutA 命令可以查看对象的内存布局,利用vs2008调试界面查看对象的内存布局往往是不全的,不推荐采用此种方式。下面为A的类布局。
在64位的linux的g++下测试X、Y、Z、A的大小分别为1、8、8、16,这是因为指针的大小为8个字节。
一个类占用的空间比类本身非静态数据成员空间大的原因有如下两点:
编译器自动加上额外的数据成员,用来支持某些语言特性,例如virtual特性。
内存边界调整的需要
3.1 数据成员的绑定 味同嚼蜡的章节。
3.2 数据成员的布局 数据成员在内存中的布局顺序跟数据成员在类中的声明顺序是一致的,而且现在的编译器都不关心数据成员在类中是public、protected还是private的。
为了内存对齐,编译器在变量之间插入了空白字节,不同的编译器内存对齐的原则并不一致。
为了实现虚函数机制,编译器插入了vptr成员变量。
以上这些内容,本章节并没有展开详解。
3.3 数据成员变量的存取 数据成员包括静态数据成员和非静态数据成员。
静态数据成员变量放在静态存储区,不会造成任何空间或执行时间上的浪费。
对于非静态数据成员,无论成员变量是struct数据成员、类数据成员、单一继承、多重继承情况下执行效率完全一样。执行效率较静态数据成员变量稍低。
1 2 3 4 5 6 7 8 class Test { public: int a; int b; int c; }; Test test;
在上述例子中要想读取test.c的位置,编译器需要执行类似这样的操作:&test + &Test::c,可以看出对类中变量的存取成本多了一个算数运算。
对于虚拟继承的情况由于需要在运行期才能决定存取操作,需要一些额外的成本,在下文讨论。
3.4 继承与数据成员 如果类中不包含继承机制,则数据成员的布局和struct中数据成员的布局是一致的。
本节将从单一继承但不包含虚函数、单一继承包含虚函数、多重继承、虚拟继承四个方面讨论数据成员变量。陈浩有几篇博文对此进行了详细的解释,比书上内容要易懂和全面,这几篇文章必看。
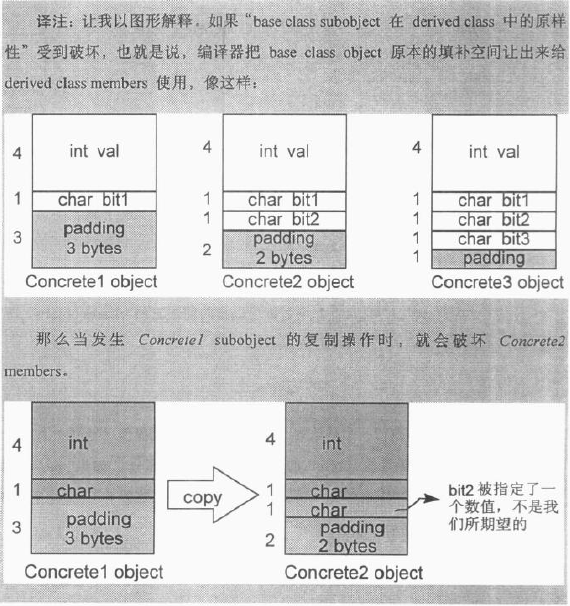
单一继承且不包含虚函数 书中举例解释了为什么类继承时类成员之间的填补空白会比单个类时要多,下图的内存布局图中Concrete3继承自Concrete2,Concrete2继承自Concrete1。Concrete3类占用的空间大小为:bit1占用的1个字节+3个字节的空白,bit2占用的1字节+3字节的空白,bit3占用的1字节+3字节空白。如果Concrete3不继承自任何对象,而是包含bit1、bit2、bit3三个变量,占用的空间大小为1+1+1+1=4。
之所以编译器在继承机制中会作如此处理,是为了在继承机制中对象之间的默认按比特复制操作更方便。例如:
1 2 Concrete1 *p1 = new Concrete1, *p2 = new Concrete2; *p2 = *p1;
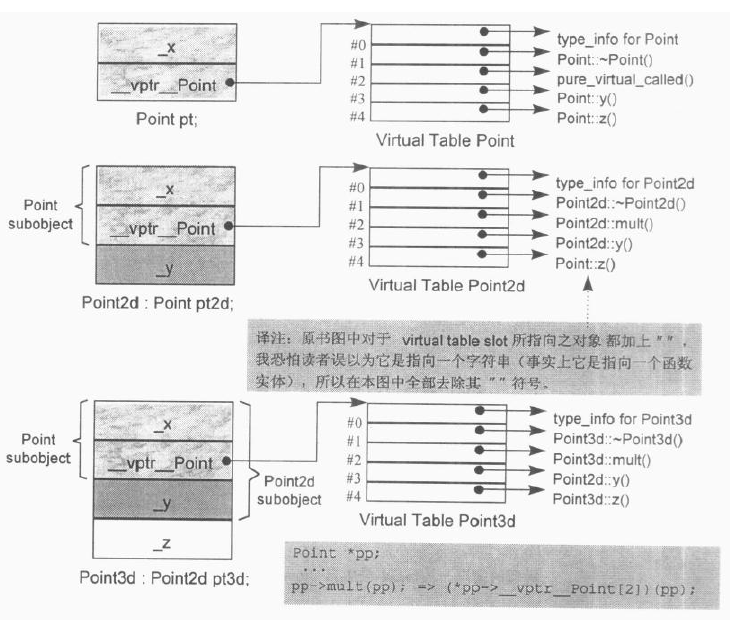
单一继承包含虚函数 假设有如下类定义
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 class Base { public : Base () { printf ("Base\n" ); } virtual ~Base () { printf ("~Base\n" ); } virtual void foo () int base_x; }; class Derived : public Base{ public : Derived () { printf ("Derived\n" ); } ~Derived () { printf ("~Derived\n" ); } void foo () int derived_y; };
则Derived类的对象模型如下,通过图可以非常清晰的理解单一继承包含虚函数的情况:
多重继承 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 class Base1 { public : Base1 () { printf ("Base1\n" ); } virtual ~Base1 () { printf ("~Base1\n" ); } virtual void base1_virtual_func () int base1_x; }; class Base2 { public : Base2 () { printf ("Base2\n" ); } virtual ~Base2 () { printf ("~Base2\n" ); } void base2_not_virtual_func () int base2_x; }; class Derived : public Base1, public Base2{ public : Derived () { printf ("Derived\n" ); } ~Derived () { printf ("~Derived\n" ); } void derived_func () void base1_virtual_func () int derived_y; };
则Vertex3d类的对象模型如下,同样通过图可以非常清晰的理解多重继承的情况:
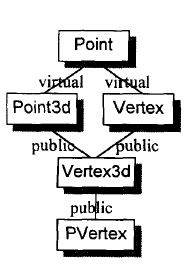
重复继承 书中并没有涉及到重复继承,重复继承是指某个基类被间接重复继承了多次,属于重复继承和钻石级多重虚拟继承的过渡情况,有必要说明一下。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 class Base { public : virtual void base_virtual_func () void base_func () int base_x; }; class Base1 : public Base{ public : Base1 () { printf ("Base1\n" ); } virtual ~Base1 () { printf ("~Base1\n" ); } virtual void base_virtual_func () virtual void base1_virtual_func () int base1_x; }; class Base2 : public Base{ public : Base2 () { printf ("Base2\n" ); } virtual ~Base2 () { printf ("~Base2\n" ); } virtual void base_virtual_func () void base2_not_virtual_func () int base2_x; }; class Derived : public Base1, public Base2{ public : Derived () { printf ("Derived\n" ); } ~Derived () { printf ("~Derived\n" ); } void derived_func () void base1_virtual_func () int derived_y; };
通过下图的对象模型可以看出,重复继承的类Base在Derived的实例中存在两份,要想直接更改Base类中的base_x变量的值,不能通过derived.base_x = 1直接赋值的方式,需要调用derived.Base1::base_x = 1的方式来更改,更改后的效果仅更改了Base1对象对应的Base类实例中的base_x的值。
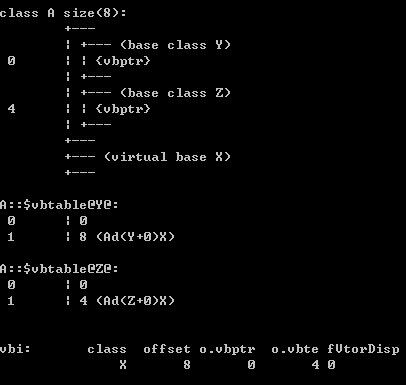
钻石型多重虚拟继承 该种方式的继承已经是所有继承中最为复杂的了。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 class Base { public : virtual void base_virtual_func () void base_func () int base_x; }; class Base1 : virtual public Base{ public : Base1 () { printf ("Base1\n" ); } virtual ~Base1 () { printf ("~Base1\n" ); } virtual void base_virtual_func () virtual void base1_virtual_func () int base1_x; }; class Base2 : virtual public Base{ public : Base2 () { printf ("Base2\n" ); } virtual ~Base2 () { printf ("~Base2\n" ); } void base2_not_virtual_func () int base2_x; }; class Derived : public Base1, public Base2{ public : Derived () { printf ("Derived\n" ); } ~Derived () { printf ("~Derived\n" ); } void derived_func () void base1_virtual_func () int derived_y; };
在下图标出的区域中,我认为Base应该是不存在的,这里只是vs2013为了展示的考虑而添加上的。虚拟继承基类Base位于Derived类对象的除该成员外的最后位置。
对象成员的效率 作者经过试验测试,继承下的类成员读写效率跟读写普通变量效率相差不大,虚拟继承对程序的读写效率有影响。这跟理论上相差不大。
指向数据成员的指针 小技巧:可以通过&类名::变量名的语法来获取类成员变量在类对象中的位置,即相对于类对象起始地址的偏移量。
书中后面的内容个人感觉没有必要看了。