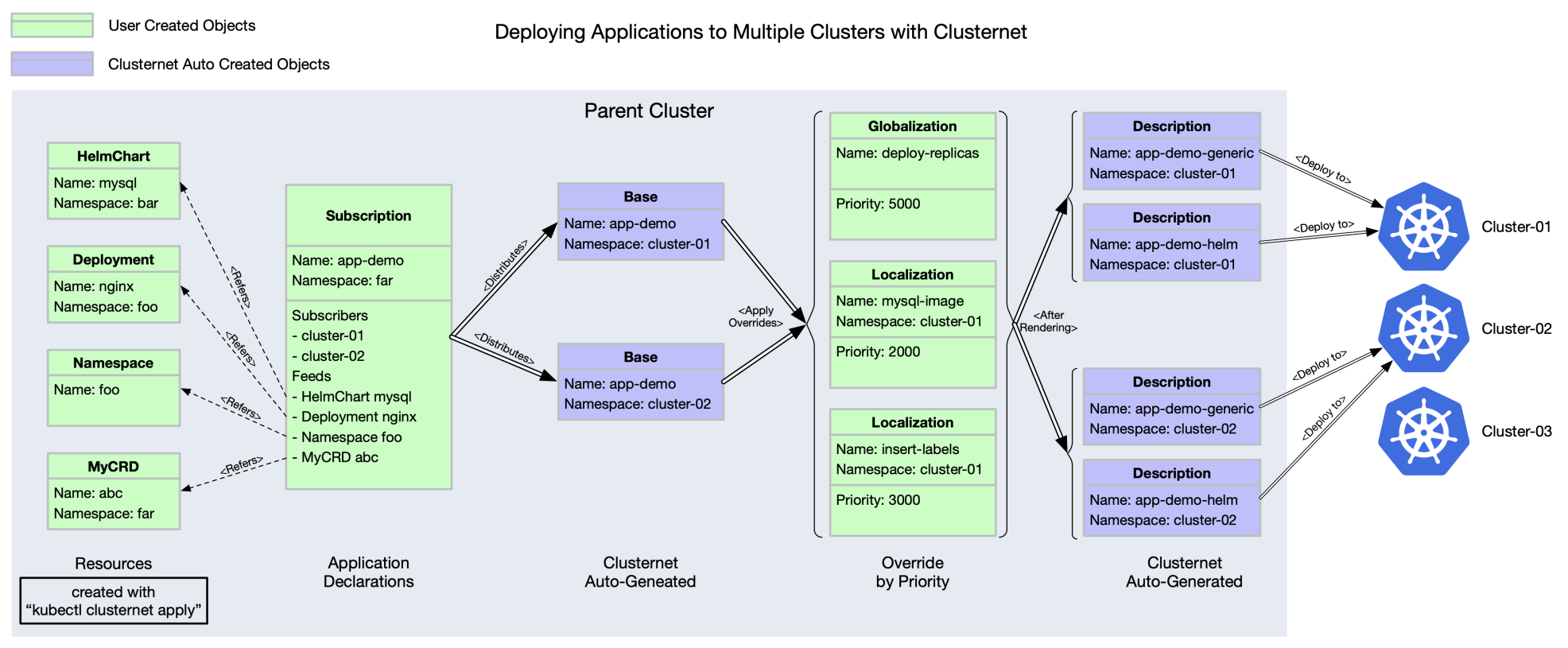
# lsblk -o name,size,type,rota,mountpoint NAME SIZE TYPE ROTA MOUNTPOINT vdc 20G disk 1 /var/lib/kubelet/pods/eea3a54c-b211-4ee3-bcbe-70ba3fe84c05/volumes/kubernetes.io~csi/d-t4n36xdqey47v9e0ej8r/mount vda 120G disk 1 └─vda1 120G part 1 /
kubectl get nodes -o=custom-columns=NodeName:.metadata.name,TaintKey:.spec.taints[*].key,TaintValue:.spec.taints[*].value,TaintEffect:.spec.taints[*].effect
2. 查看不ready的pod
1
kubectl get pod --all-namespaces -o wide -w | grep -vE "Com|NAME|Running|1/1|2/2|3/3|4/4"
3. pod按照重启次数排序
1
kubectl get pods -A --sort-by='.status.containerStatuses[0].restartCount' | tail
kubectl get pod -n kube-system -o=custom-columns=NAME:.metadata.name,NAMESPACE:.metadata.namespace,PHASE:.status.phase,Request-cpu:.spec.containers\[0\].resources.requests.cpu,Request-memory:.spec.containers\[0\].resources.requests.memory,Limit-cpu:.spec.containers\[0\].resources.limits.cpu,Limit-memory:.spec.containers\[0\].resources.limits.memory
得到的效果如下:
1 2 3 4 5
NAME NAMESPACE PHASE Request-cpu Request-memory Limit-cpu Limit-memory cleanup-for-np-processor-9pjkm kube-system Succeeded <none> <none> <none> <none> coredns-6c6664b94-7rnm8 kube-system Running 100m 70Mi <none> 170Mi coredns-6c6664b94-djxch kube-system Failed 100m 70Mi <none> 170Mi coredns-6c6664b94-khvrb kube-system Running 100m 70Mi <none> 170Mi
# 会安装如下两个deployment,其中一个是controller,另外一个是webhook $ kubectl get deploy -n kube-federation-system NAME READY UP-TO-DATE AVAILABLE AGE kubefed-admission-webhook1/1117m40s kubefed-controller-manager2/2227m40s
$ k get FederatedTypeConfig -n kube-federation-system NAME AGE clusterrolebindings.rbac.authorization.k8s.io 19h clusterroles.rbac.authorization.k8s.io 19h configmaps 19h deployments.apps 19h ingresses.extensions 19h jobs.batch 19h namespaces 19h replicasets.apps 19h secrets 19h serviceaccounts 19h services 19h
将crd资源类型集群联邦,执行 kubefedctl enable 命令
1 2 3 4
$ kubefedctl enable customresourcedefinitions I1224 20:32:54.537112687543 util.go:141] Api resource found. customresourcedefinition.apiextensions.k8s.io/federatedcustomresourcedefinitions.types.kubefed.io created federatedtypeconfig.core.kubefed.io/customresourcedefinitions.apiextensions.k8s.io created in namespace kube-federation-system
$ k get crd federatedcustomresourcedefinitions.types.kubefed.io NAME CREATED AT federatedcustomresourcedefinitions.types.kubefed.io 2021-12-24T12:32:54Z
$ kubefedctl enable clusterrolebinding I1225 01:46:42.779166818254 util.go:141] Api resource found. customresourcedefinition.apiextensions.k8s.io/federatedclusterrolebindings.types.kubefed.io created federatedtypeconfig.core.kubefed.io/clusterrolebindings.rbac.authorization.k8s.io created in namespace kube-federation-system
apiVersion: v1 kind: Secret metadata: # Name MUST be of form "bootstrap-token-<token id>" name: bootstrap-token-07401b namespace: kube-system
# Type MUST be 'bootstrap.kubernetes.io/token' type: bootstrap.kubernetes.io/token stringData: # Human readable description. Optional. description: "The bootstrap token used by clusternet cluster registration."
# Token ID and secret. Required. token-id: 07401b token-secret: f395accd246ae52d
# Extra groups to authenticate the token as. Must start with "system:bootstrappers:" auth-extra-groups: system:bootstrappers:clusternet:register-cluster-token
// This is the ONLY place you need to wrap for Clusternet config.Wrap(func(rt http.RoundTripper) http.RoundTripper { return clientgo.NewClusternetTransport(config.Host, rt) })
// now we could create and visit all the resources client := kubernetes.NewForConfigOrDie(config) _, err = client.CoreV1().Namespaces().Create(context.TODO(), &corev1.Namespace{ ObjectMeta: metav1.ObjectMeta{ Name: "demo", }, }, metav1.CreateOptions{})


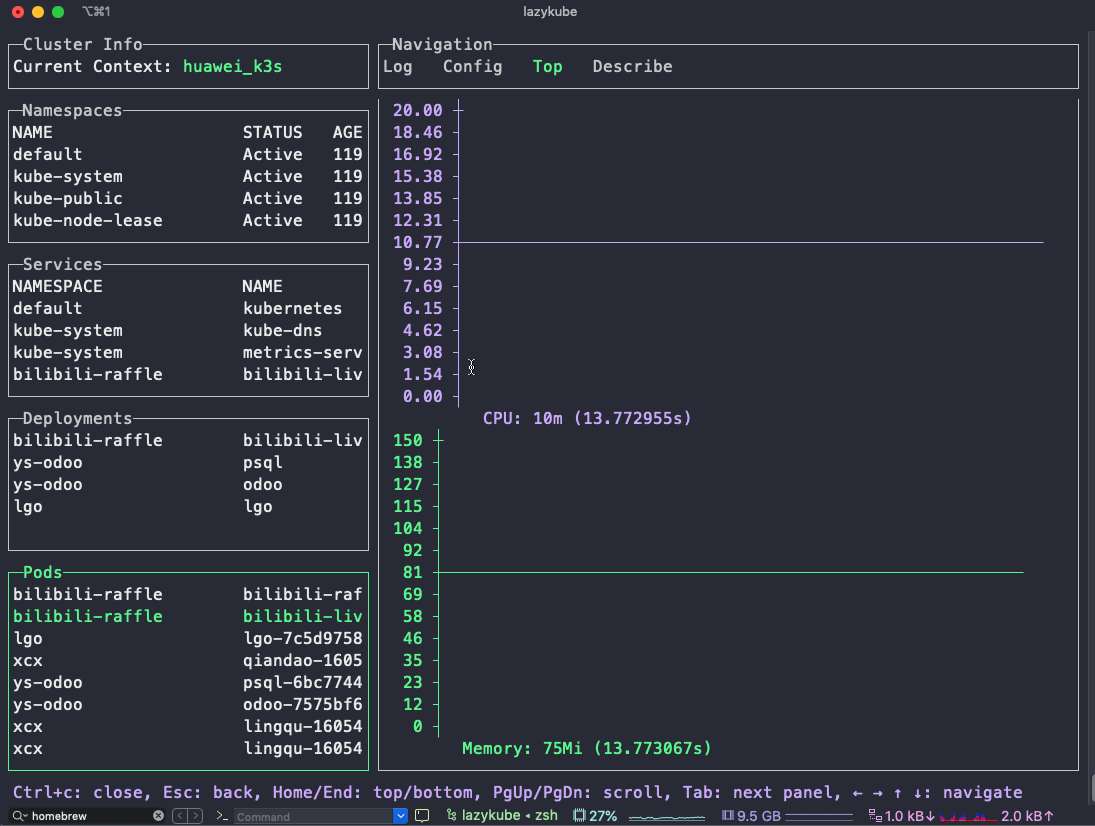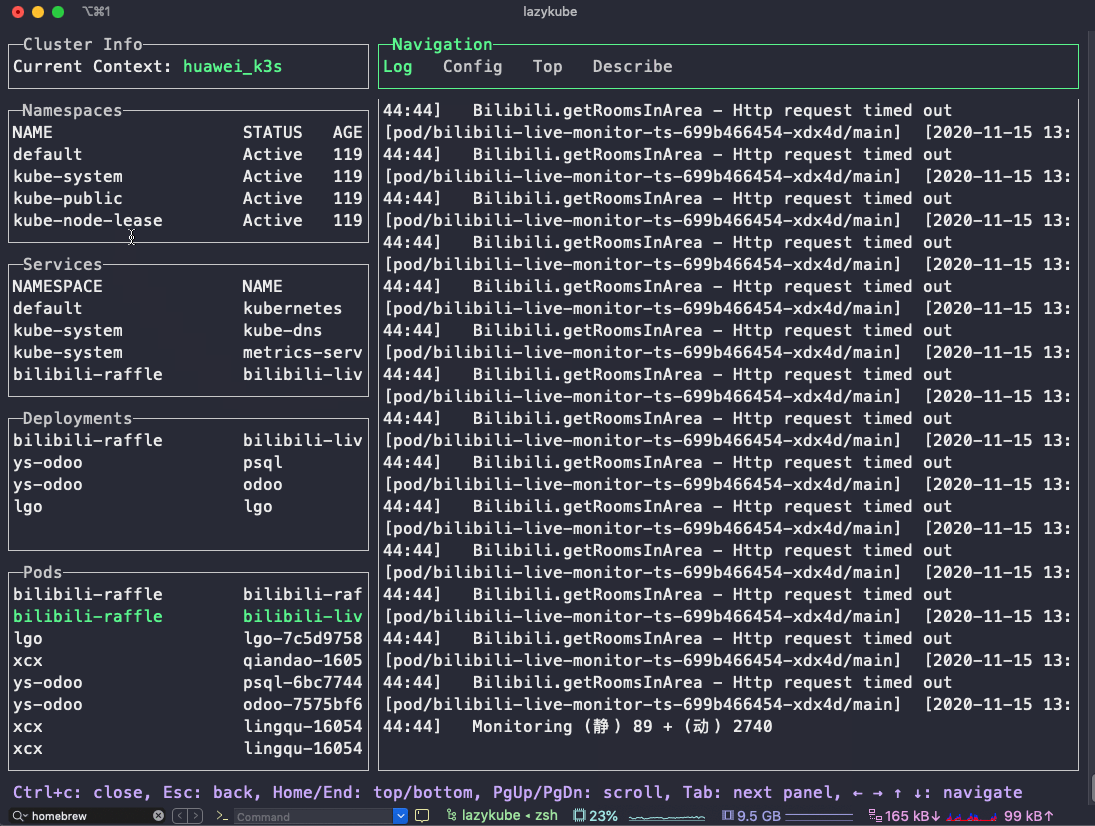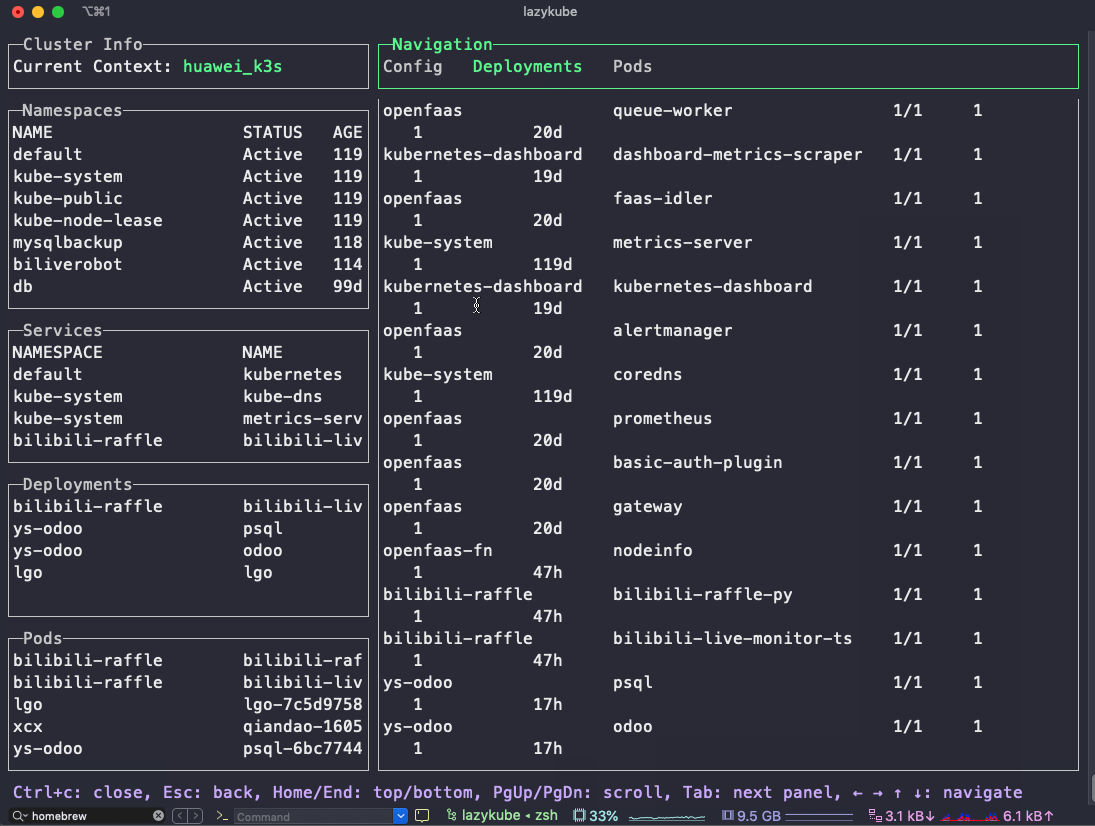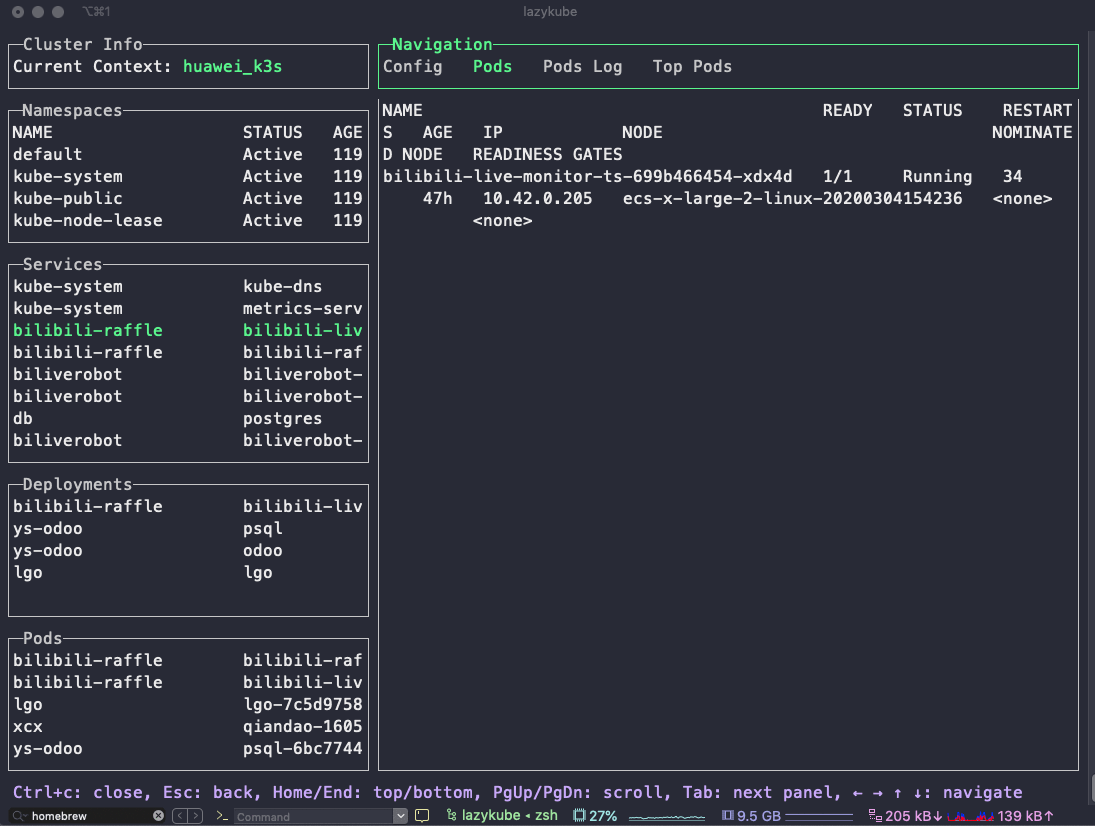


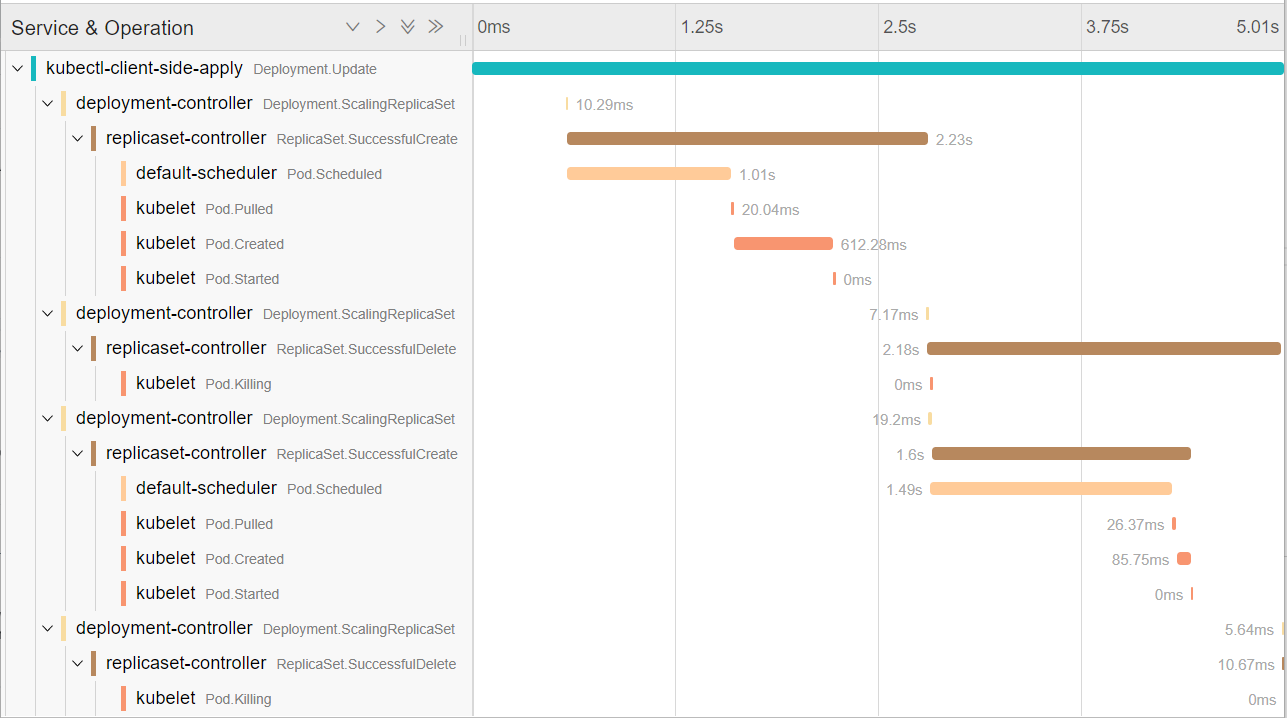
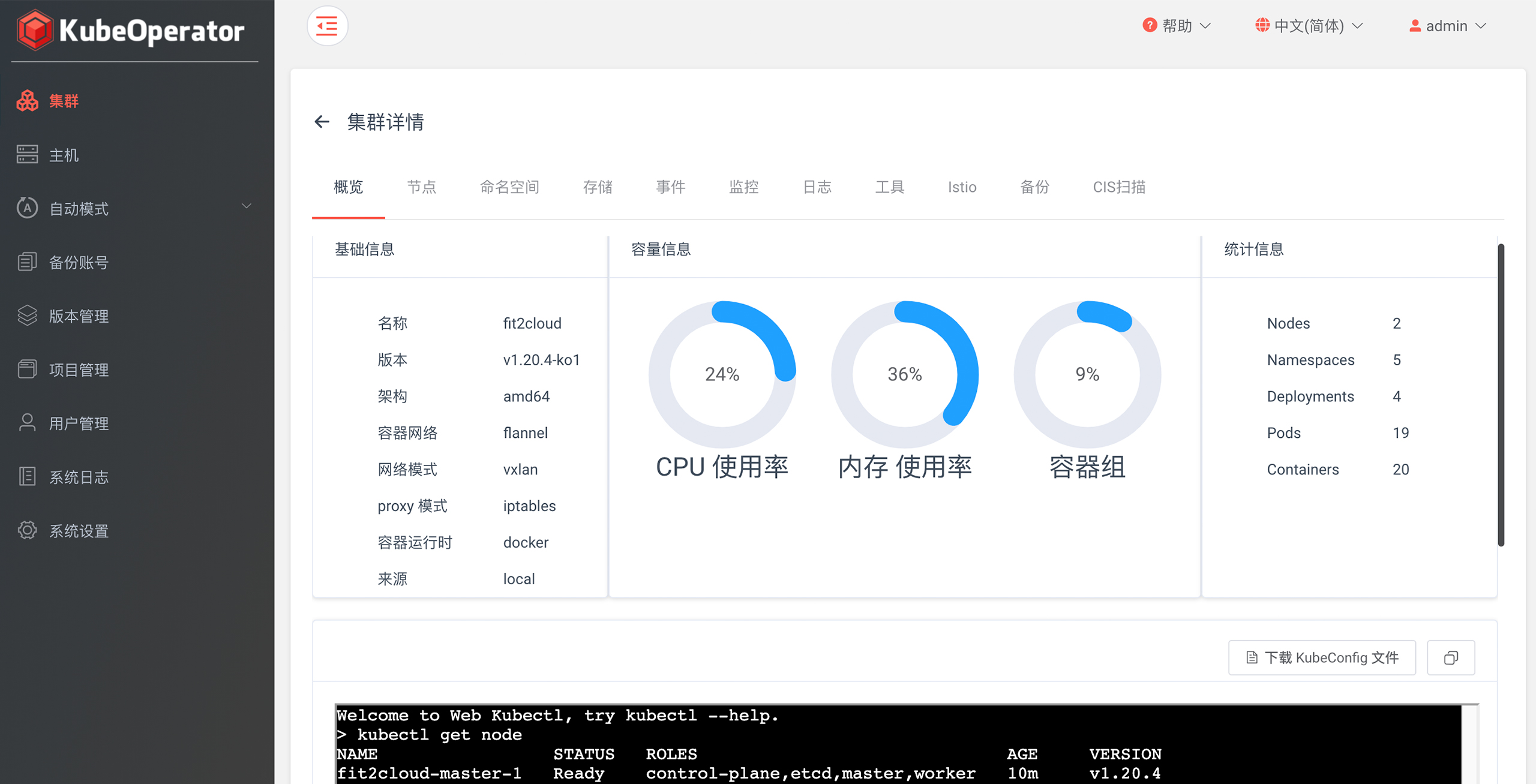
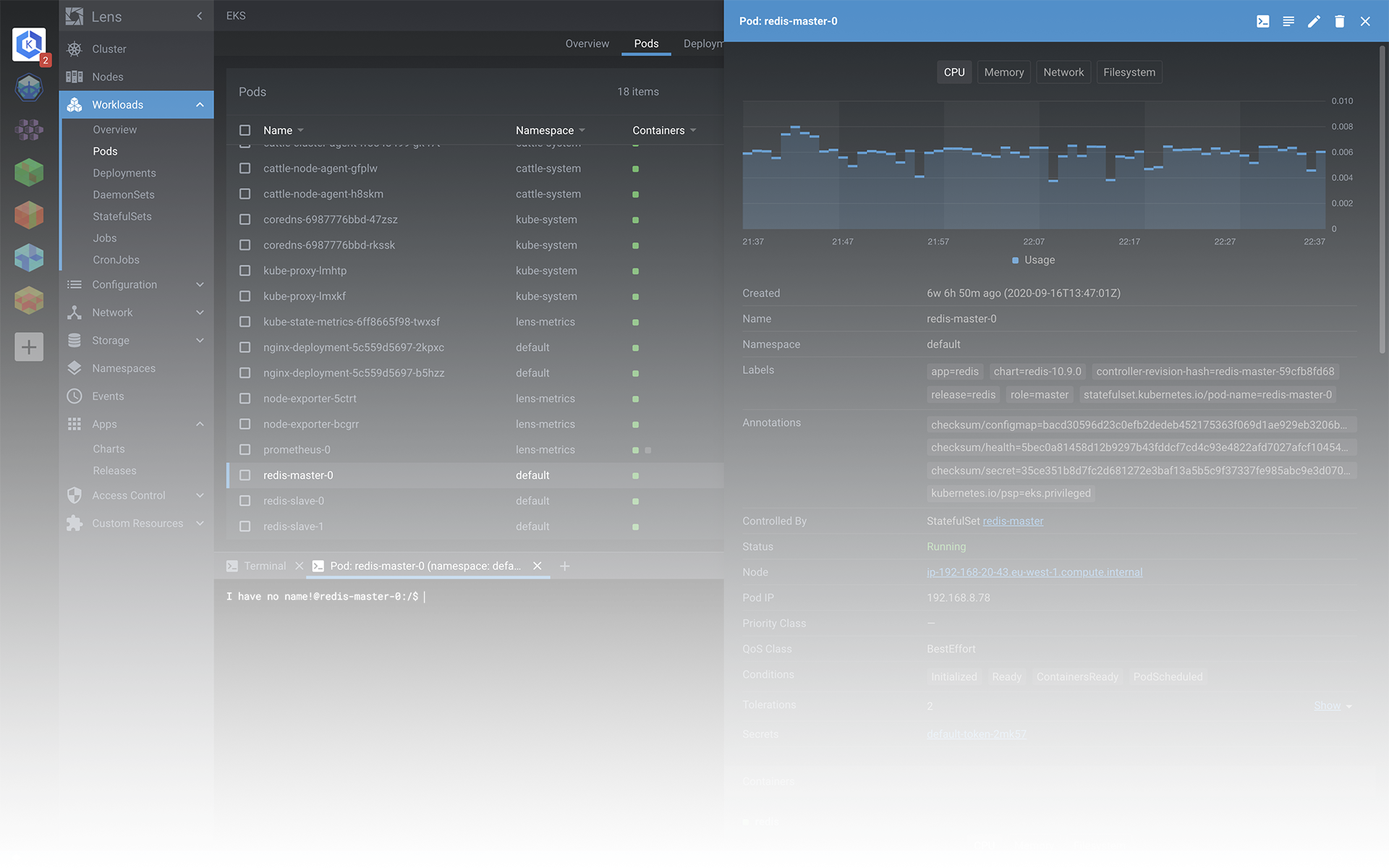
](https://kuring.oss-cn-beijing.aliyuncs.com/common/kube-eventer.png)