kubectl get nodes -o=custom-columns=NodeName:.metadata.name,TaintKey:.spec.taints[*].key,TaintValue:.spec.taints[*].value,TaintEffect:.spec.taints[*].effect
2. 查看不ready的pod
1
kubectl get pod --all-namespaces -o wide -w | grep -vE "Com|NAME|Running|1/1|2/2|3/3|4/4"
3. pod按照重启次数排序
1 2 3
kubectl get pods -A --sort-by='.status.containerStatuses[0].restartCount' | tail
kubectl get pod -A --no-headers | sort -k5 -nr | head
kubectl get pod -n kube-system -o=custom-columns=NAME:.metadata.name,NAMESPACE:.metadata.namespace,PHASE:.status.phase,Request-cpu:.spec.containers\[0\].resources.requests.cpu,Request-memory:.spec.containers\[0\].resources.requests.memory,Limit-cpu:.spec.containers\[0\].resources.limits.cpu,Limit-memory:.spec.containers\[0\].resources.limits.memory
得到的效果如下:
1 2 3 4 5
NAME NAMESPACE PHASE Request-cpu Request-memory Limit-cpu Limit-memory cleanup-for-np-processor-9pjkm kube-system Succeeded <none> <none> <none> <none> coredns-6c6664b94-7rnm8 kube-system Running 100m 70Mi <none> 170Mi coredns-6c6664b94-djxch kube-system Failed 100m 70Mi <none> 170Mi coredns-6c6664b94-khvrb kube-system Running 100m 70Mi <none> 170Mi
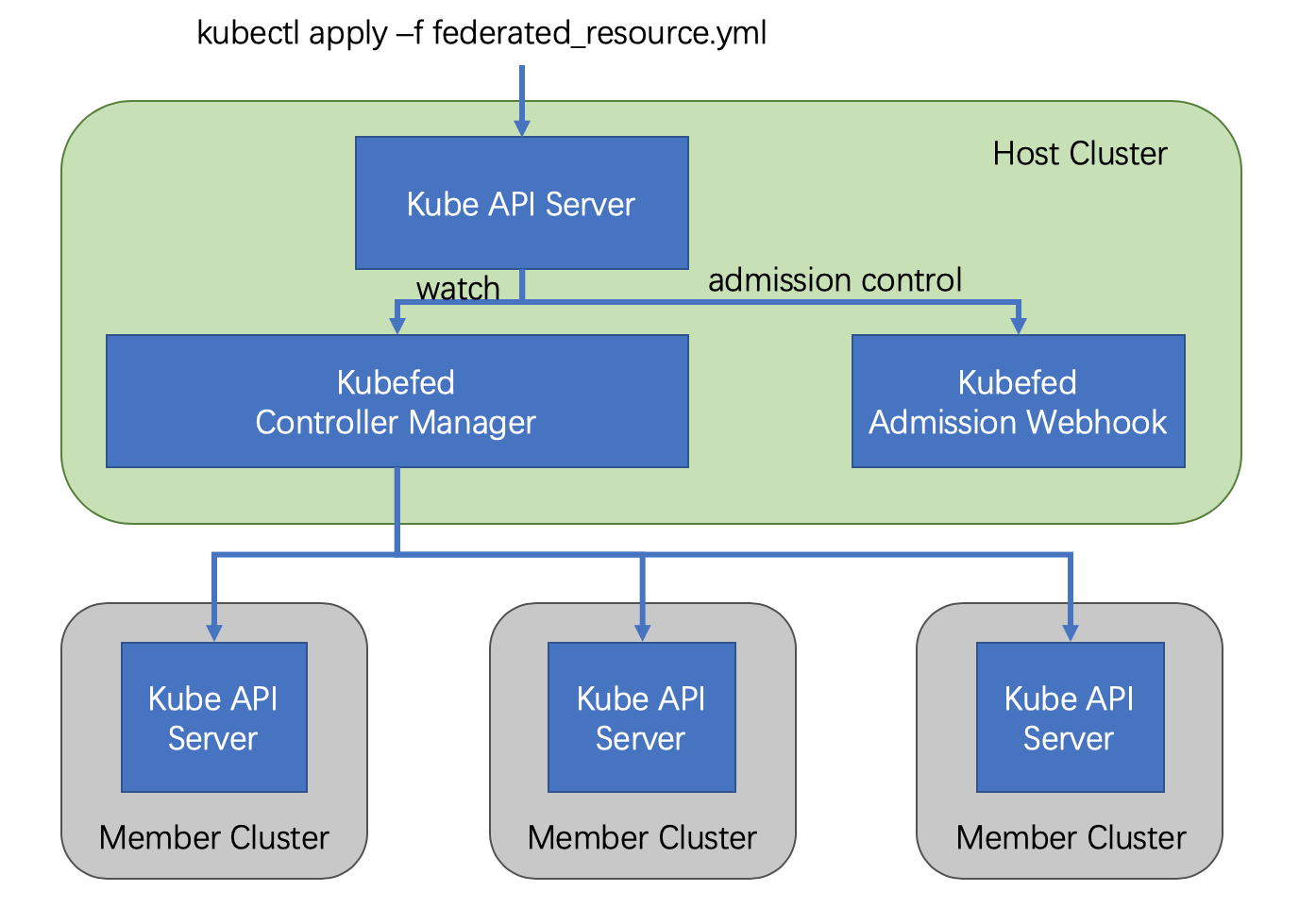
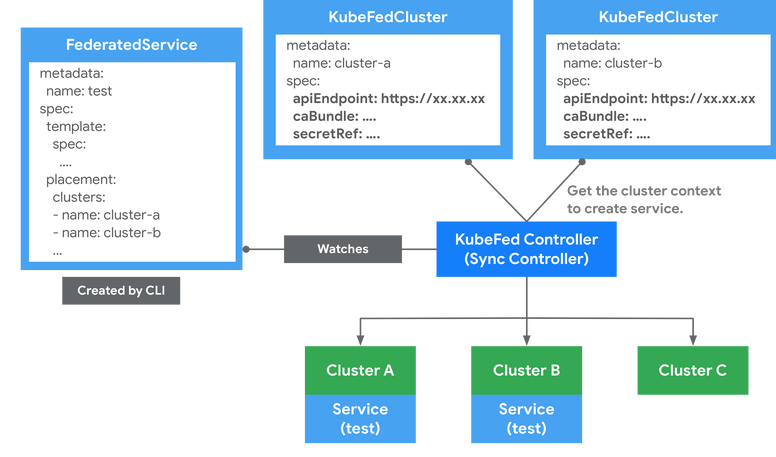
# 会安装如下两个deployment,其中一个是controller,另外一个是webhook $ kubectl get deploy -n kube-federation-system NAME READY UP-TO-DATE AVAILABLE AGE kubefed-admission-webhook1/1117m40s kubefed-controller-manager2/2227m40s
$ k get FederatedTypeConfig -n kube-federation-system NAME AGE clusterrolebindings.rbac.authorization.k8s.io 19h clusterroles.rbac.authorization.k8s.io 19h configmaps 19h deployments.apps 19h ingresses.extensions 19h jobs.batch 19h namespaces 19h replicasets.apps 19h secrets 19h serviceaccounts 19h services 19h
将crd资源类型集群联邦,执行 kubefedctl enable 命令
1 2 3 4
$ kubefedctl enable customresourcedefinitions I1224 20:32:54.537112687543 util.go:141] Api resource found. customresourcedefinition.apiextensions.k8s.io/federatedcustomresourcedefinitions.types.kubefed.io created federatedtypeconfig.core.kubefed.io/customresourcedefinitions.apiextensions.k8s.io created in namespace kube-federation-system
$ k get crd federatedcustomresourcedefinitions.types.kubefed.io NAME CREATED AT federatedcustomresourcedefinitions.types.kubefed.io 2021-12-24T12:32:54Z
$ kubefedctl enable clusterrolebinding I1225 01:46:42.779166818254 util.go:141] Api resource found. customresourcedefinition.apiextensions.k8s.io/federatedclusterrolebindings.types.kubefed.io created federatedtypeconfig.core.kubefed.io/clusterrolebindings.rbac.authorization.k8s.io created in namespace kube-federation-system
apiVersion: v1 kind: Secret metadata: # Name MUST be of form "bootstrap-token-<token id>" name: bootstrap-token-07401b namespace: kube-system
# Type MUST be 'bootstrap.kubernetes.io/token' type: bootstrap.kubernetes.io/token stringData: # Human readable description. Optional. description: "The bootstrap token used by clusternet cluster registration."
# Token ID and secret. Required. token-id: 07401b token-secret: f395accd246ae52d
# Extra groups to authenticate the token as. Must start with "system:bootstrappers:" auth-extra-groups: system:bootstrappers:clusternet:register-cluster-token
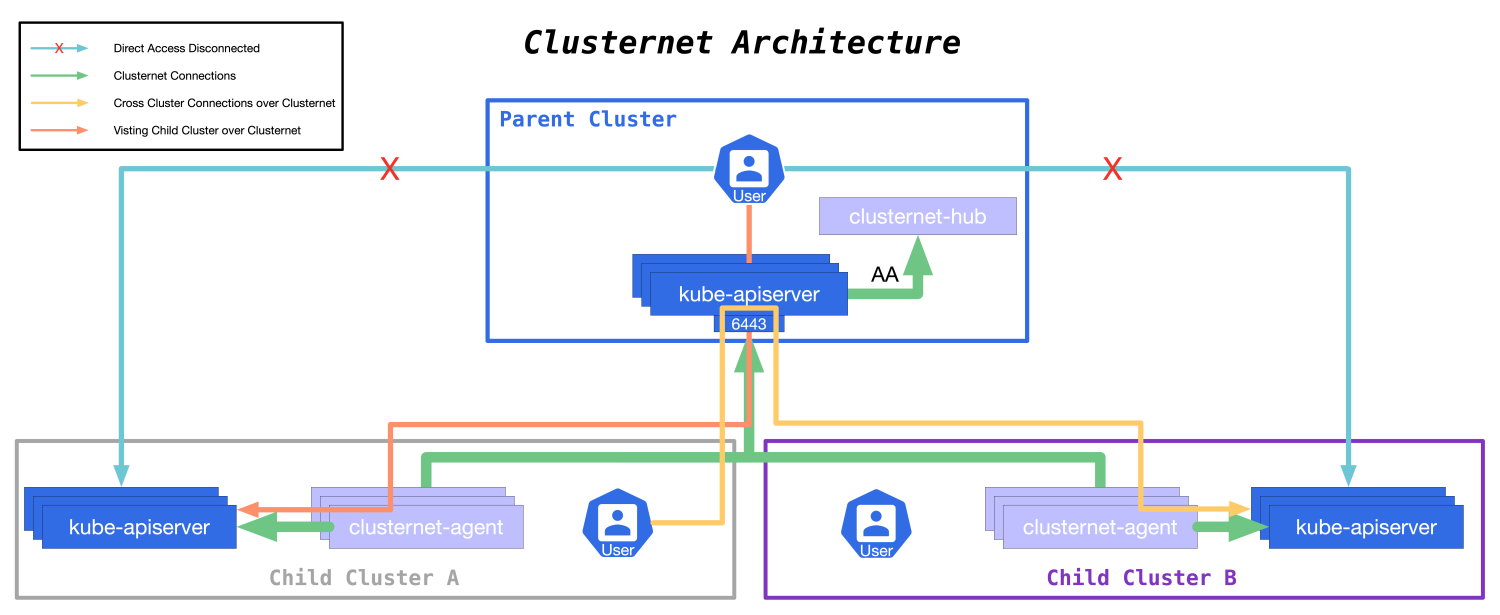
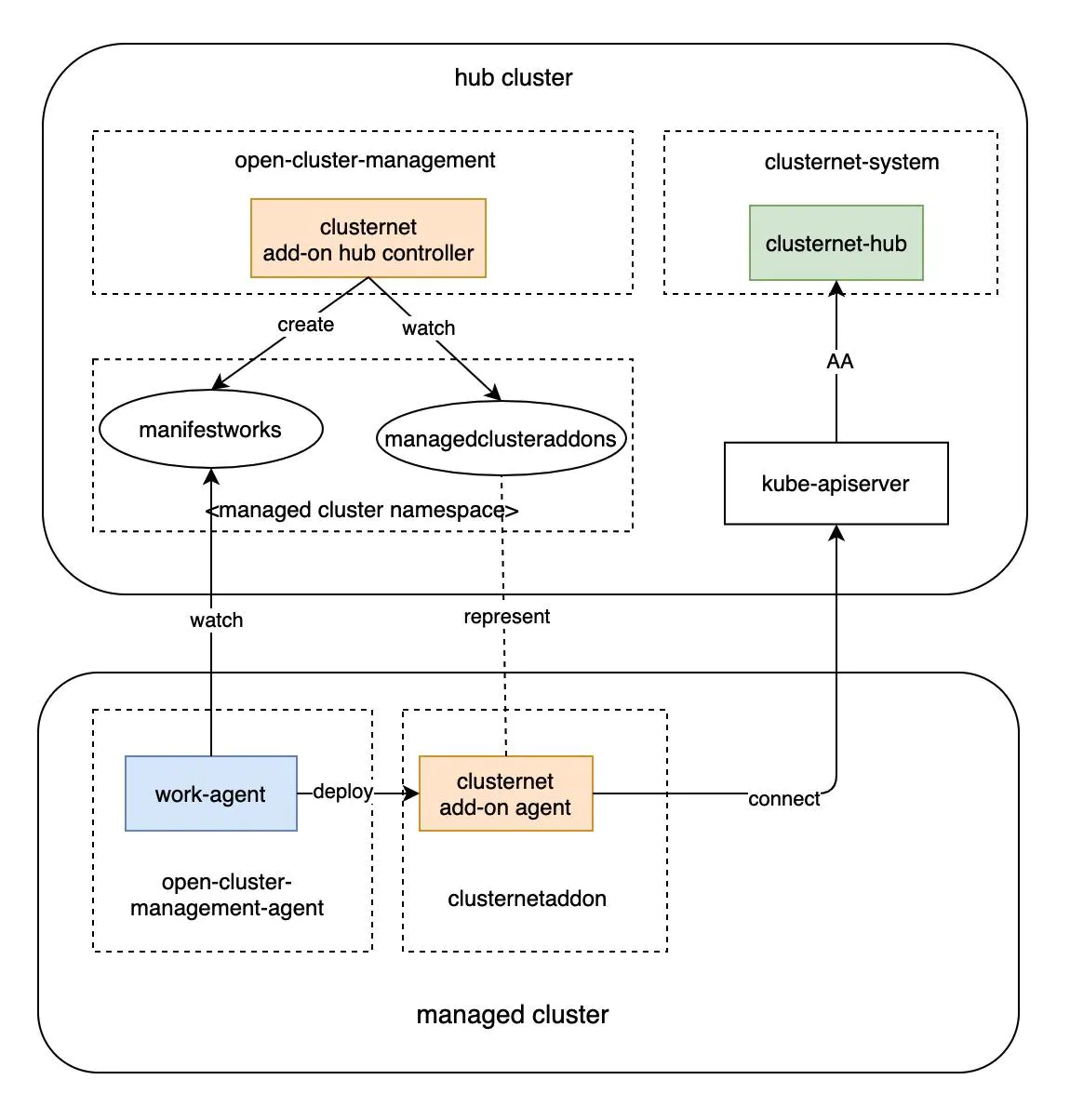
// This is the ONLY place you need to wrap for Clusternet config.Wrap(func(rt http.RoundTripper) http.RoundTripper { return clientgo.NewClusternetTransport(config.Host, rt) })
// now we could create and visit all the resources client := kubernetes.NewForConfigOrDie(config) _, err = client.CoreV1().Namespaces().Create(context.TODO(), &corev1.Namespace{ ObjectMeta: metav1.ObjectMeta{ Name: "demo", }, }, metav1.CreateOptions{})
# fdisk /dev/sda Welcome to fdisk (util-linux 2.23.2).
Changes will remain in memory only, until you decide to write them. Be careful before using the write command.
# 创建主分区2,空间为1g,磁盘格式为lvm Command (m for help): n Partition type: p primary (1 primary, 0 extended, 3 free) e extended Select (default p): p Partition number (2-4, default 2): 2 First sector (83886080-167772159, default 83886080): Using default value 83886080 Last sector, +sectors or +size{K,M,G} (83886080-167772159, default 167772159): +1G Partition 2 of type Linux and of size 1 GiB is set
Command (m for help): t Partition number (1,2, default 2): 2 Hex code (type L to list all codes): 8e Changed type of partition 'Linux' to 'Linux LVM'
# 创建主分区3,空间为5g,磁盘格式为lvm Command (m for help): n Partition type: p primary (2 primary, 0 extended, 2 free) e extended Select (default p): p Partition number (3,4, default 3): 3 First sector (85983232-167772159, default 85983232): Using default value 85983232 Last sector, +sectors or +size{K,M,G} (85983232-167772159, default 167772159): +5G Partition 3 of type Linux and of size 5 GiB is set
Command (m for help): t Partition number (1-3, default 3): 3 Hex code (type L to list all codes): 8e Changed type of partition 'Linux' to 'Linux LVM'
# 保存上述操作 Command (m for help): w The partition table has been altered!
Calling ioctl() to re-read partition table.
WARNING: Re-reading the partition table failed with error 16: Device or resource busy. The kernel still uses the old table. The new table will be used at the next reboot or after you run partprobe(8) or kpartx(8) Syncing disks.
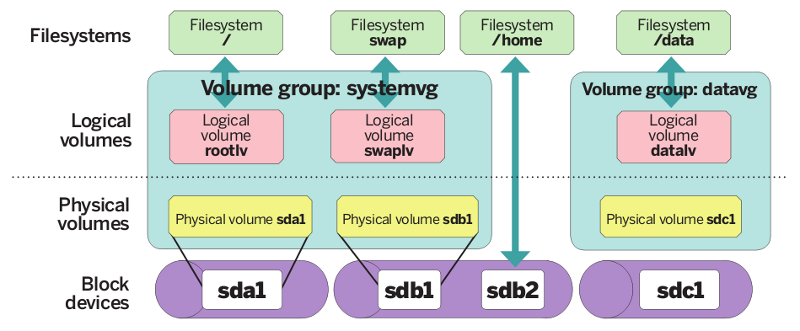
当前磁盘空间状态如下:
1 2 3 4 5 6 7 8 9 10 11 12 13
# fdisk -l
Disk /dev/sda: 85.9 GB, 85899345920 bytes, 167772160 sectors Units = sectors of 1 * 512 = 512 bytes Sector size (logical/physical): 512 bytes / 512 bytes I/O size (minimum/optimal): 512 bytes / 512 bytes Disk label type: dos Disk identifier: 0x000a05f8
Device Boot Start End Blocks Id System /dev/sda1 * 2048 83886079 41942016 83 Linux /dev/sda2 83886080 85983231 1048576 8e Linux LVM /dev/sda3 85983232 96468991 5242880 8e Linux LVM
# pvcreate /dev/sda2 /dev/sda3 Physical volume "/dev/sda2" successfully created. Physical volume "/dev/sda3" successfully created. [root@localhost vagrant]# pvdisplay "/dev/sda2" is a new physical volume of "1.00 GiB" --- NEW Physical volume --- PV Name /dev/sda2 VG Name PV Size 1.00 GiB Allocatable NO PE Size 0 Total PE 0 Free PE 0 Allocated PE 0 PV UUID MgarF2-Ka6D-blDi-8ecd-1SEU-y2GD-JtiK2c
"/dev/sda3" is a new physical volume of "5.00 GiB" --- NEW Physical volume --- PV Name /dev/sda3 VG Name PV Size 5.00 GiB Allocatable NO PE Size 0 Total PE 0 Free PE 0 Allocated PE 0 PV UUID ToKp2T-30mS-0P8c-ZrcB-2lO4-ayo9-62fuDx
# vgcreate vg1 /dev/sda1 # vgdisplay -v --- Volume group --- VG Name vg1 System ID Format lvm2 Metadata Areas 2 Metadata Sequence No 1 VG Access read/write VG Status resizable MAX LV 0 Cur LV 0 Open LV 0 Max PV 0 Cur PV 2 Act PV 2 VG Size 5.99 GiB PE Size 4.00 MiB Total PE 1534 Alloc PE / Size 0 / 0 Free PE / Size 1534 / 5.99 GiB VG UUID XI8Biv-JtUv-tsur-wuvm-IJQz-HLZu-6a2u5G
--- Physical volumes --- PV Name /dev/sda2 PV UUID MgarF2-Ka6D-blDi-8ecd-1SEU-y2GD-JtiK2c PV Status allocatable Total PE / Free PE 255 / 255
PV Name /dev/sda3 PV UUID ToKp2T-30mS-0P8c-ZrcB-2lO4-ayo9-62fuDx PV Status allocatable Total PE / Free PE 1279 / 1279
# lvdisplay --- Logical volume --- LV Path /dev/vg1/lv1 LV Name lv1 VG Name vg1 LV UUID EesY4i-lSqY-ef1R-599C-XTrZ-IcVL-P7W46Q LV Write Access read/write LV Creation host, time localhost.localdomain, 2019-06-16 07:29:38 +0000 LV Status available # open 0 LV Size 2.00 GiB Current LE 512 Segments 1 Allocation inherit Read ahead sectors auto - currently set to 8192 Block device 253:0
# mkfs.ext4 /dev/vg1/lv1 mke2fs 1.42.9 (28-Dec-2013) Filesystem label= OS type: Linux Block size=4096 (log=2) Fragment size=4096 (log=2) Stride=0 blocks, Stripe width=0 blocks 131072 inodes, 524288 blocks 26214 blocks (5.00%) reserved for the super user First data block=0 Maximum filesystem blocks=536870912 16 block groups 32768 blocks per group, 32768 fragments per group 8192 inodes per group Superblock backups stored on blocks: 32768, 98304, 163840, 229376, 294912
Allocating group tables: done Writing inode tables: done Creating journal (16384 blocks): done Writing superblocks and filesystem accounting information: done
# lvextend -L +1G /dev/vg1/lv1 Size of logical volume vg1/lv1 changed from 2.00 GiB (512 extents) to 3.00 GiB (768 extents). Logical volume vg1/lv1 successfully resized.
# resize2fs /dev/vg1/lv1 resize2fs 1.42.9 (28-Dec-2013) Filesystem at /dev/vg1/lv1 is mounted on /tmp/lvm; on-line resizing required old_desc_blocks = 1, new_desc_blocks = 1 The filesystem on /dev/vg1/lv1 is now 786432 blocks long.
lvremove操作执行的时候经常会出现提示“Logical volume xx contains a filesystem in use.”的情况,该问题一般是由于有其他进程在使用该文件系统导致的。网络上经常看到的是通过fuser或者lsof命令来查找使用方,但偶尔该命令会失效,尤其在本机上有容器的场景下。另外一个可行的办法是通过 grep -nr "/data" /proc/*/mount 命令,可以找到挂载该目录的所有进程,简单有效。
$ pvdisplay "/dev/vdb" is a new physical volume of "100.00 GiB" --- NEW Physical volume --- PV Name /dev/vdb VG Name PV Size 100.00 GiB Allocatable NO PE Size 0 Total PE 0 Free PE 0 Allocated PE 0 PV UUID 8NnlYc-4f3f-fkeW-a3l3-LXoC-9UEH-fvpb5V
"/dev/vdc" is a new physical volume of "200.00 GiB" --- NEW Physical volume --- PV Name /dev/vdc VG Name PV Size 200.00 GiB Allocatable NO PE Size 0 Total PE 0 Free PE 0 Allocated PE 0 PV UUID I9ffpN-c1vc-PQOB-yKyd-MdzO-Ngff-6e116t
$ vgcreate vg1 /dev/vdb /dev/vdc Volume group "vg1" successfully created
$ vgdisplay --- Volume group --- VG Name vg1 System ID Format lvm2 Metadata Areas 2 Metadata Sequence No 1 VG Access read/write VG Status resizable MAX LV 0 Cur LV 0 Open LV 0 Max PV 0 Cur PV 2 Act PV 2 VG Size 299.99 GiB PE Size 4.00 MiB Total PE 76798 Alloc PE / Size 0 / 0 Free PE / Size 76798 / 299.99 GiB VG UUID Gi0bJx-jqY8-YpSo-kB0l-9wdk-ZfCT-GpgFZY
$ lvdisplay --- Logical volume --- LV Path /dev/vg1/lv1 LV Name lv1 VG Name vg1 LV UUID JQZ193-dz6A-I0Ue-rTKC-6XrQ-gb1F-Qy9kDl LV Write Access read/write LV Creation host, time iZt4nd6wiprf8foracovwqZ, 2022-01-08 23:28:45 +0800 LV Status available # open 0 LV Size 299.99 GiB Current LE 76798 Segments 2 Allocation inherit Read ahead sectors auto - currently set to 256 Block device 252:0
$ lvdisplay --- Logical volume --- LV Path /dev/vg1/lv1 LV Name lv1 VG Name vg1 LV UUID FnOmCM-IkuE-3Rvv-fQqk-Cv1Q-lb8S-l5X7O3 LV Write Access read/write LV Creation host, time iZt4nd6wiprf8foracovwqZ, 2022-01-09 00:07:08 +0800 LV Status available # open 0 LV Size 50.00 GiB Current LE 12800 Segments 1 Allocation inherit Read ahead sectors auto - currently set to 256 Block device 252:0
// parseConfig returns a parsed configuration for an Azure cloudprovider config file funcparseConfig(configReader io.Reader) (*Config, error) { var config Config
// The resource group name may be in different cases from different Azure APIs, hence it is converted to lower here. // See more context at https://github.com/kubernetes/kubernetes/issues/71994. config.ResourceGroup = strings.ToLower(config.ResourceGroup) return &config, nil }
// NewAlreadyExistsError returns a new instance of AlreadyExists error. funcNewAlreadyExistsError(operationName string)error { return alreadyExistsError{operationName} }
// IsAlreadyExists returns true if an error returned from // NestedPendingOperations indicates a new operation can not be started because // an operation with the same operation name is already executing. funcIsAlreadyExists(err error)bool { switch err.(type) { case alreadyExistsError: returntrue default: returnfalse } }
type alreadyExistsError struct { operationName string }
var _ error = alreadyExistsError{}
func(err alreadyExistsError) Error() string { return fmt.Sprintf( "Failed to create operation with name %q. An operation with that name is already executing.", err.operationName) }
还可以延伸出更复杂一些的树形error体系:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17
// package net
type Error interface { error Timeout() bool// Is the error a timeout? Temporary() bool// Is the error temporary? }
type UnknownNetworkError string
func(e UnknownNetworkError) Error() string
func(e UnknownNetworkError) Temporary() bool
func(e UnknownNetworkError) Timeout() bool
Error Wrapping
error类型仅包含一个字符串类型的信息,如果函数的调用栈信息为A -> B -> C,如果函数C返回err,在函数A处打印err信息,那么很难判断出err的真正出错位置,不利于快速定位问题。我们期望的效果是在函数A出打印err,能够精确的找到err的源头。