File "/usr/lib64/python2.7/site-packages/jinja2/sandbox.py", line 22, in <module> from markupsafe import EscapeFormatter ImportError: cannot import name EscapeFormatter
pkts bytes target prot opt in out source destination 349K 21M KUBE-SERVICES all -- * * 0.0.0.0/0 0.0.0.0/0 /* kubernetes service portals */
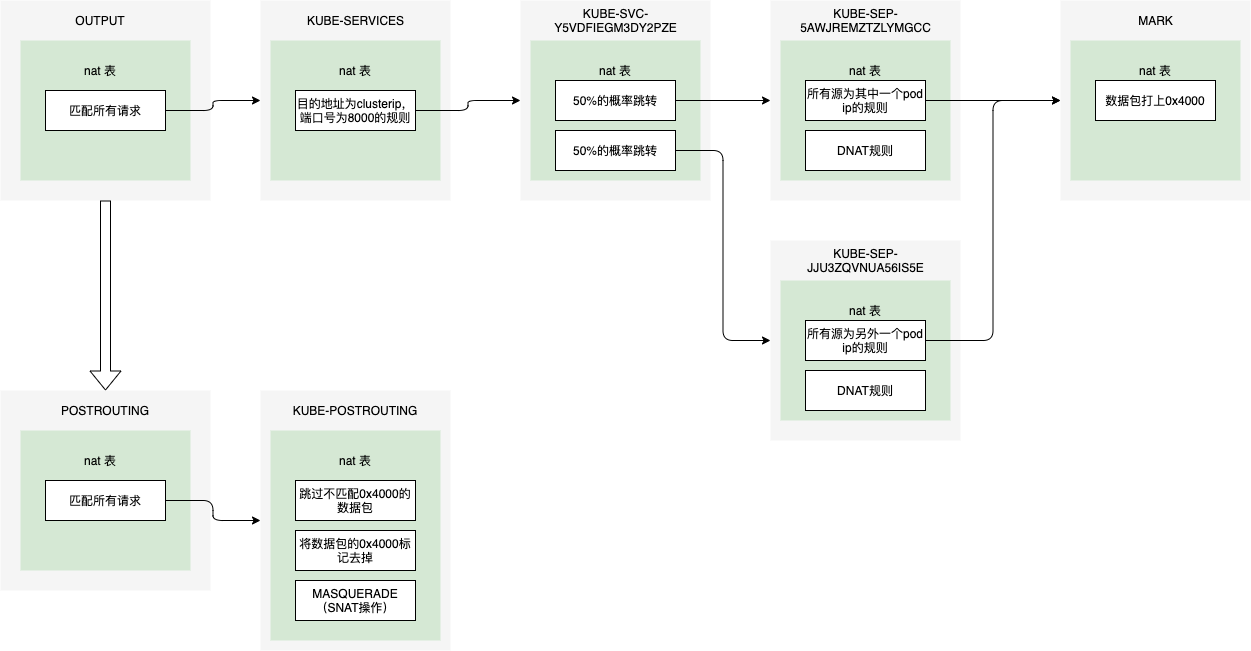
在KUBE-SERVICES链的最后一条规则为跳转到KUBE-NODEPORTS链
1
4079 246K KUBE-NODEPORTS all -- * * 0.0.0.0/0 0.0.0.0/0 /* kubernetes service nodeports; NOTE: this must be the last rule in this chain */ ADDRTYPE match dst-type LOCAL
# 10.149.112.0/23为pod网段 -A KUBE-XLB-76HLDRT5IPNSMPF5 -s 10.149.112.0/23 -m comment --comment "Redirect pods trying to reach external loadbalancer VIP to clusterIP" -j KUBE-SVC-76HLDRT5IPNSMPF5 -A KUBE-XLB-76HLDRT5IPNSMPF5 -m comment --comment "Balancing rule 0 for acs-system/nginx-ingress-lb-cloudbiz:http" -j KUBE-SEP-XZXLBWOKJBSJBGVU
-A KUBE-SVC-76HLDRT5IPNSMPF5 -m statistic --mode random --probability 0.50000000000 -j KUBE-SEP-XZXLBWOKJBSJBGVU -A KUBE-SVC-76HLDRT5IPNSMPF5 -j KUBE-SEP-GP4UCOZEF3X7PGLR
-A KUBE-SEP-XZXLBWOKJBSJBGVU -s 10.149.112.45/32 -j KUBE-MARK-MASQ -A KUBE-SEP-XZXLBWOKJBSJBGVU -p tcp -m tcp -j DNAT --to-destination 10.149.112.45:80 -A KUBE-SEP-GP4UCOZEF3X7PGLR -s 10.149.112.46/32 -j KUBE-MARK-MASQ -A KUBE-SEP-GP4UCOZEF3X7PGLR -p tcp -m tcp -j DNAT --to-destination 10.149.112.46:80
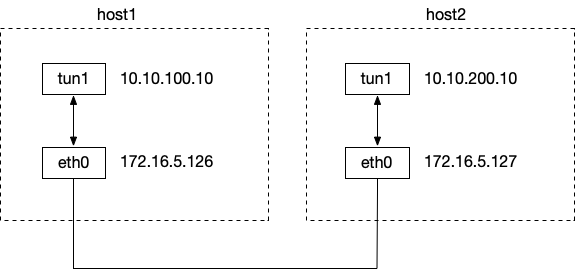
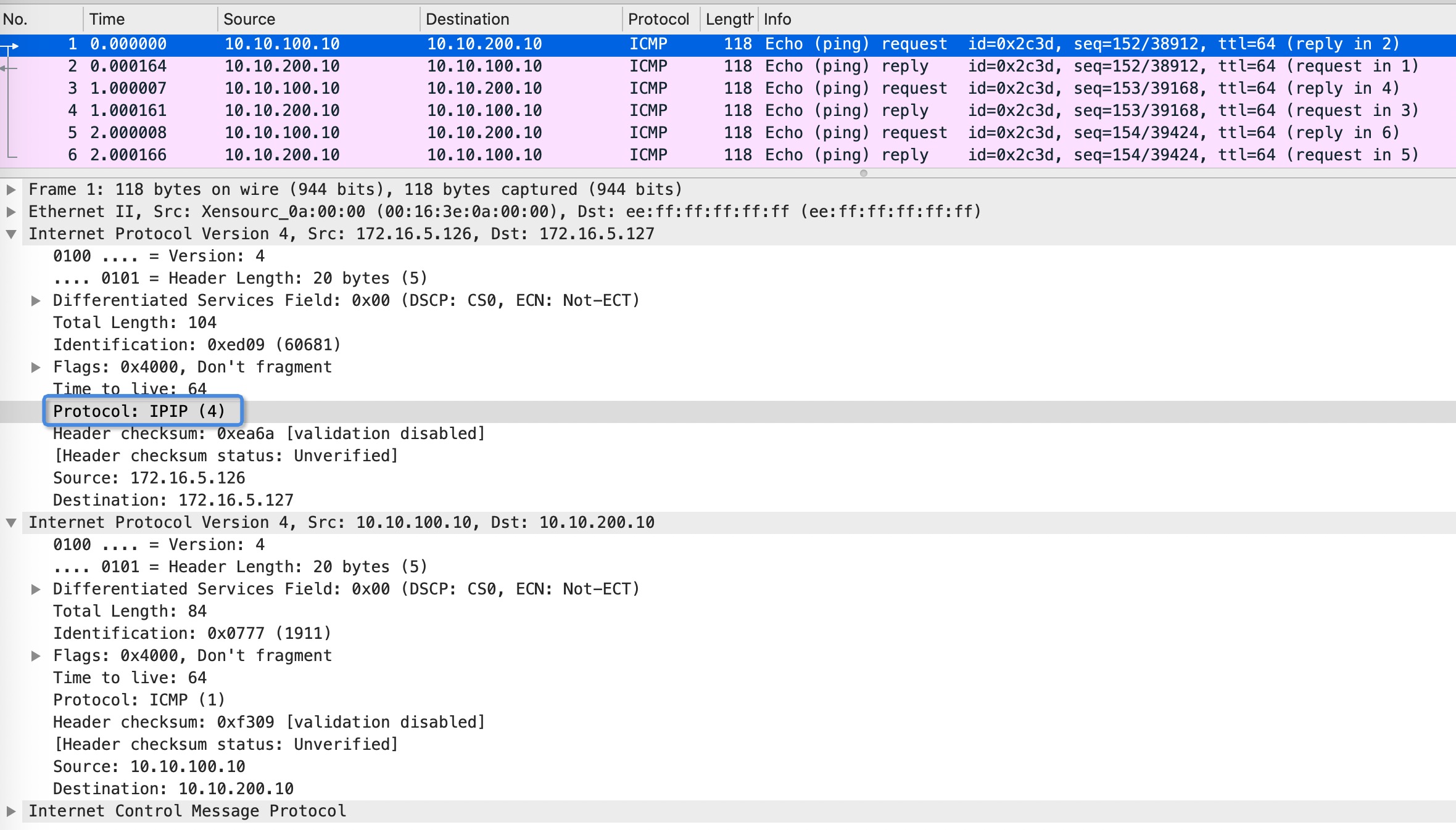
# 用来创建tun1设备,并ipip协议的外层ip,目的ip为172.16.5.127, 源ip为172.16.5.126 ip tunnel add tun1 mode ipip remote 172.16.5.127 local 172.16.5.126 # 给tun1设备增加ip地址,并设置tun1设备的对端ip地址为10.10.200.10 ip addr add 10.10.100.10 peer 10.10.200.10 dev tun1 ip link set tun1 up
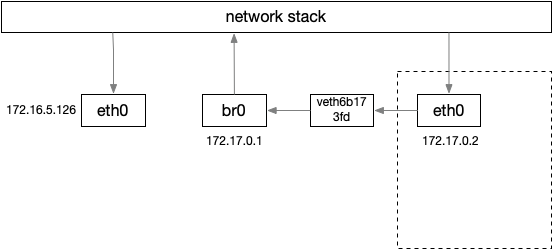
$ ip link show eth0 3: eth0@if18: <BROADCAST,MULTICAST,UP,LOWER_UP,M-DOWN> mtu 1500 qdisc noqueue state UP link/ether 96:5f:80:a3:a3:01 brd ff:ff:ff:ff:ff:ff
$ ip addr 18: veth0e09999e@if3: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue master br0 state UP group default link/ether de:b0:74:89:e8:3e brd ff:ff:ff:ff:ff:ff link-netnsid 4 inet6 fe80::dcb0:74ff:fe89:e83e/64 scope link valid_lft forever preferred_lft forever