本文绝大多数题目来源于网络,部分题目为原创。
slice相关 以下代码有什么问题,说明原因 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 type student struct { Name string Age int } func pase_student () m := make (map [string ]*student) stus := []student{ {Name: "zhou" , Age: 24 }, {Name: "li" , Age: 23 }, {Name: "wang" , Age: 22 }, } for _, stu := range stus { m[stu.Name] = &stu } }
每次遍历的时候stu变量为值拷贝,stu变量的地址未改变,即&stu未改变,遍历结束后stu指向stus中的最后一个元素。
使用reflect.TypeOf(str)打印出的类型为main.student,如果使用stu.Age += 10这样的语法是不会修改stus中的值的。
可修改为如下形式:
1 2 3 for i, _ := range stus { m[stus[i].Name] = &stus[i] }
有一个slice of object, 遍历slice修改name为指定的值 1 2 3 4 5 6 7 8 type foo struct { name string value string } func mutate(s []foo, name string) { // TODO }
意在考察range遍历的时候是值拷贝,以及slice的内部数据结构,slice的数据结构如下:
1 2 3 4 5 6 struct Slice { // must not move anything byte* array; // actual data uintgo len; // number of elements uintgo cap; // allocated number of elements };
执行append函数后会返回一个新的Slice对象,新的Slice对象跟旧Slice对象共用相同的数据存储,但是len的值并不相同。
该题目中,可以通过下面的方式来修改值:
1 2 3 4 5 6 7 8 9 // range方式 for i, _ := range s { s[i].name = name } // for i形式 for i:=0; i<len(s); i++ { s[i].name = name }
从slice中找到一个元素匹配name,并将该元素的指针添加到一个新的slice中,返回新slice 1 2 3 4 func find(s []foo, name string) []*foo { // TODO }
仍旧是考察range是值拷贝的用法,此处使用for i 循环即可
1 2 3 4 5 6 7 8 9 10 11 func find(s []foo, name string) []*foo { res := []*foo{} for i := 0; i < len(s); i++ { if s[i].name == name { res = append(res, &(s[i])) break } } return res }
下面输出什么内容 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 package main import "fmt" func m(s []int) { s[0] = -1 s = append(s, 4) } func main() { s1 := []int{1, 2, 3} m(s1) s2 := make([]int, 3, 6) m(s2) s2 = append(s2, 7) s3 := [3]int{1, 2, 3} fmt.Println(s1) fmt.Println(s2) fmt.Println(s3) }
slice的函数传递为值拷贝方式,在函数m中对下标为0的元素的修改会直接修改原slice中的值,因为slice中的指针指向的地址是相同的。
append之后的slice虽然可能是在原数组上增加了元素,但原slice中的len字段并没有变化。
make([]int, 3, 6)虽然指定了slice的cap,但对于append没有影响,还是会在slice中最后一个元素的下一个位置增加新元素。
数组由于是值拷贝,对新数组的修改不会影响到原数组。
输出内容如下:
1 2 3 [-1 2 3] [-1 0 0 7] [1 2 3]
下面输出什么内容 该题目为我自己想出来的,非来自于互联网,意在考察对slice和append函数的理解。
1 2 3 4 5 6 7 8 9 func f() { s1 := make([]int, 2, 8) fmt.Println(s1) s2 := append(s1, 4) fmt.Println(s2) s3 := append(s1, 5) fmt.Println(s3) fmt.Println(s2) }
输出结果如下,在执行第二个append后,第一个append在内存中增加的元素4会被5覆盖掉。执行结果可以通过fmt.Println(s1, cap(s1), &s1[0])的形式将第一个元素的内存地址打印出来查看。
goroutine 以下代码输出内容: 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 package main import ( "fmt" "runtime" ) func main() { runtime.GOMAXPROCS(1) go func() { fmt.Println(1) }() for { } fmt.Println(1) }
不会有任何输出
下面输出的内容 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 type People struct {}func (p *People) fmt.Println("showA" ) p.ShowB() } func (p *People) fmt.Println("showB" ) } type Teacher struct { People } func (t *Teacher) fmt.Println("teacher showB" ) } func main () t := Teacher{} t.ShowA() }
输出
有点出乎意料,可以举个反例,如果ShowA()方法会调用到Teacher类型的ShowB()方法,假设People和Teacher并不在同一个包中时,编译一定会出现错误。
Go中没有继承机制,只有组合机制。
下面代码会触发异常吗?请详细说明 1 2 3 4 5 6 7 8 9 10 11 12 13 func main() { runtime.GOMAXPROCS(1) int_chan := make(chan int, 1) string_chan := make(chan string, 1) int_chan <- 1 string_chan <- "hello" select { case value := <-int_chan: fmt.Println(value) case value := <-string_chan: panic(value) } }
会间歇性触发异常,select会随机选择。
以下代码能编译过去吗?为什么? 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 package main import ( "fmt" ) type People interface { Speak(string) string } type Student struct{} func (stu *Student) Speak(think string) (talk string) { if think == "bitch" { talk = "You are a good boy" } else { talk = "hi" } return } func main() { var peo People = Student{} think := "bitch" fmt.Println(peo.Speak(think)) }
不能编译过去,提示Stduent does not implement People (Speak method has pointer receiver),将Speak定义更改为func (stu Stduent) Speak(think string) (talk string)即可编译通过。
main的调用方式更改为如下也可以编译通过var peo People = new(Stduent)。
func (stu *Stduent) Speak(think string) (talk string)是*Student类型的方法,不是Stduent类型的方法。
下面输出什么 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 package main import ( "fmt" "time" "runtime" ) func main() { runtime.GOMAXPROCS(1) arr := [10000]int{} for i:=0; i<len(arr); i++ { arr[i] = i } for _, a := range arr { go func() { fmt.Println(a) }() } for { time.Sleep(time.Second) } }
一直输出9999.涉及到goroutine的切换时机,仅系统调用或者有函数调用的情况下才会切换goroutine,for循环情况下一直没有系统调用或函数切换发生,需要等到for循环结束后才会启动新的goroutine。
以下代码打印出来什么内容,说出为什么。。。 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 package main import ( "fmt" ) type People interface { Show() } type Student struct{} func (stu *Student) Show() { } func live() People { var stu *Student return stu } func main() { if live() == nil { fmt.Println("AAAAAAA") } else { fmt.Println("BBBBBBB") } }
打印BBBBBBB。
byte与rune的关系
byte alias for uint8
rune alias for uint32,用来表示unicode
1 2 3 4 5 6 7 8 func main() { // range遍历为rune类型,输出int32 for _, w:=range "123" { fmt.Printf("%T", w) } // 取数组为byte类型,输出uint8 fmt.Printf("%T", "123"[0]) }
写出打印的结果 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 type People struct { name string `json:"name"` } func main () js := `{ "name":"11" }` var p People p.name = "123" err := json.Unmarshal([]byte (js), &p) if err != nil { fmt.Println("err: " , err) return } fmt.Println("people: " , p) }
打印结果为people: {123}
下面函数有什么问题? 1 2 3 func funcMui(x,y int)(sum int,error){ return x+y,nil }
函数返回值命名 在函数有多个返回值时,只要有一个返回值有指定命名,其他的也必须有命名。 如果返回值有有多个返回值必须加上括号; 如果只有一个返回值并且有命名也需要加上括号; 此处函数第一个返回值有sum名称,第二个为命名,所以错误。
以下函数输出什么 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 package main func main() { println(DeferFunc1(1)) println(DeferFunc2(1)) println(DeferFunc3(1)) println(DeferFunc4(1)) } func DeferFunc1(i int) (t int) { t = i defer func() { t += 3 }() return t } func DeferFunc2(i int) int { t := i defer func() { t += 3 }() return t } func DeferFunc3(i int) (t int) { defer func() { t += i }() return 2 } func DeferFunc4(i int) (t int) { t = 10 return 2 }
输出结果为: 4 1 3 2
return语句不是一个原子指令,分为两个阶段,执行return后面的表达式和返回表达式的结果。defer函数在返回表达式之前执行。
执行return后的表达式给返回值赋值
调用defer函数
空的return
DeferFunc1在第一步执行表达式后t=1,执行defer后t=4,返回值为4
DeferFunc2在第一步执行表达式后t=1,执行defer后t=4,返回值为第一步表达式的结果1
DeferFunc3在第一步表达式为t=2,执行defer后t=3,返回值为t=3
DeferFunc4在第一步执行表达式后t=2,返回值为t=2
是否可以编译通过?如果通过,输出什么? 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 package main import ( "fmt" ) func main() { sn1 := struct { age int name string }{age: 11, name: "qq"} sn2 := struct { age int name string }{age: 11, name: "qq"} sn3 := struct { name string age int }{age: 11, name: "qq"} if sn1 == sn2 { fmt.Println("sn1 == sn2") } if sn1 == sn3 { fmt.Println("sn1 == sn3") } sm1 := struct { age int m map[string]string }{age: 11, m: map[string]string{"a": "1"}} sm2 := struct { age int m map[string]string }{age: 11, m: map[string]string{"a": "1"}} if sm1 == sm2 { fmt.Println("sm1 == sm2") } }
结构体比较 进行结构体比较时候,只有相同类型的结构体才可以比较,结构体是否相同不但与属性类型个数有关,还与属性顺序相关。
还有一点需要注意的是结构体是相同的,但是结构体属性中有不可以比较的类型,如map,slice。 如果该结构属性都是可以比较的,那么就可以使用“==”进行比较操作。
是否可以编译通过?如果通过,输出什么? 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 package main import ( "fmt" ) func Foo(x interface{}) { if x == nil { fmt.Println("empty interface") return } fmt.Println("non-empty interface") } func main() { var x *int = nil Foo(x) }
输出“non-empty interface”
交替打印数字和字母 使用两个 goroutine 交替打印序列,一个 goroutine 打印数字, 另外一个 goroutine 打印字母, 最终效果为: 12AB34CD56EF78GH910IJ1112KL1314MN1516OP1718QR1920ST2122UV2324WX2526YZ2728
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 package mainimport ( "fmt" "sync" ) func main () number, letter := make (chan bool ), make (chan bool ) wait := new (sync.WaitGroup) go func () num := 1 for { <-number fmt.Printf("%d%d" , num, num+1 ) num += 2 letter <- true if num > 28 { break } } wait.Done() }() go func () begin := 'A' for { <- letter if begin < 'Z' { fmt.Printf("%c%c" , begin, begin+1 ) begin+=2 number <- true } else { break } } wait.Done() }() number <- true wait.Add(2 ) wait.Wait() }
struct类型的方法调用 假设T类型的方法上接收器既有T类型的,又有T指针类型的,那么就不可以在不能寻址的T值上调用 T接收器的方法。
请看代码,试问能正常编译通过吗?
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 import ( "fmt" ) type Lili struct { Name string } func (Lili *Lili) fmt.Println("poniter" ) } func (Lili Lili) fmt.Println("reference" ) } func main () li := Lili{} li.fmtPointer() }
能正常编译通过,并输出”poniter”
请接着看以下的代码,试问能编译通过?
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 import ( "fmt" ) type Lili struct { Name string } func (Lili *Lili) fmt.Println("poniter" ) } func (Lili Lili) fmt.Println("reference" ) } func main () Lili{}.fmtPointer() }
不能编译通过。
其实在第一个代码示例中,main主函数中的“li”是一个变量,li的虽然是类型Lili,但是li是可以寻址的,&li的类型是Lili,因此可以调用 Lili的方法。
golang context包的用法
goroutine之间的传值
goroutine之间的控制
在单核cpu的情况下,下面输出什么内容? 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 package main import ( "fmt" "sync" ) func main() { wg := sync.WaitGroup{} for _, i:=range []int{1, 2, 3, 4, 5} { wg.Add(1) go func() { defer wg.Done() fmt.Println(i) } () } wg.Wait() }
考察golang的runtime机制,goroutine的切换时机只有在有系统调用或者函数调用时才会发生,本例子中的for循环结束之前不会发生goroutine的切换,所以最终输出结果为5.
下面输出什么 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 package main import ( "fmt" ) type People interface { Speak(string) string } type Stduent struct{} func (stu *Stduent) Speak(think string) (talk string) { if think == "bitch" { talk = "You are a good boy" } else { talk = "hi" } return } func main() { var peo People = Stduent{} think := "bitch" fmt.Println(peo.Speak(think)) }
编译不通过,仅*Student实现了People接口,更改为var peo People = &Student{}即可编译通过。
下面输出什么 1 2 3 4 5 6 7 8 9 10 package main const cl = 100 var bl = 123 func main() { println(&bl, bl) println(&cl, cl) }
编译失败,常量cl通常在预处理阶段会直接展开,无法取其地址。
以下代码是否存在问题,请解释你的判断和理由 1 2 3 4 5 6 7 8 import "sync" func f(m sync.Mutex) { m.Lock() defer m.Unlock() // Do something... }
Mutex对象不能被值拷贝,后续传递需要使用指针的形式
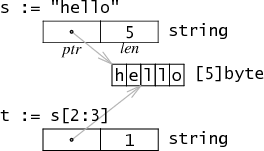
以下代码输出是什么 解释一下 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 func main() { case1() case2() } func case1() { s1 := make([]string, 1, 20) s1[0] = "hello" p1 := &s1[0] s1 = append(s1, "world") *p1 = "hello2" fmt.Printf("value of p1 is %s, value of s1[0] is %s \n", *p1, s1[0]) } func case2() { s1 := make([]string) s1[0] = "hello" p1 := &s1[0] s1 = append(s1, "world") *p1 = "hello2" fmt.Printf("value of p1 is %s, value of s1[0] is %s \n", *p1, s1[0]) }
本题意在考察string和slice的数据结构,string的数据结构如下:
case1的内存结构变化情况如下:
case2由于s1默认长度为0,直接使用s1[0]复制会出现panic错误。
ref