本文选择四台机器作为集群环境,hadoop采用0.20.2,HBase采用0.90.2,zookeeper采用独立安装的3.3.2稳定版。本文所采用的数据均为简单的测试数据,如果插入的数据量大可能会对结果产生影响。集群环境部署情况如下:
| 机器名 |
IP地址 |
用途 |
Hadoop模块 |
HBase模块 |
ZooKeeper模块 |
| server206 |
192.168.20.6 |
Master |
NameNode、JobTracker、SecondaryNameNode |
HMaster |
QuorumPeerMain |
| ap1 |
192.168.20.36 |
Slave |
DataNode、TaskTracker |
HRegionServer |
QuorumPeerMain |
| ap2 |
192.168.20.38 |
Slave |
DataNode、TaskTracker |
HRegionServer |
QuorumPeerMain |
| ap2 |
192.168.20.8 |
Slave |
DataNode、TaskTracker |
HRegionServer |
QuorumPeerMain |
单线程插入100万行
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
| import java.io.IOException;
import java.util.ArrayList;
import java.util.List;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.HColumnDescriptor;
import org.apache.hadoop.hbase.HTableDescriptor;
import org.apache.hadoop.hbase.client.HBaseAdmin;
import org.apache.hadoop.hbase.client.HTable;
import org.apache.hadoop.hbase.client.Put;
import org.apache.hadoop.hbase.util.Bytes;
public class InsertRowThreadTest {
private static Configuration conf = null;
private static String tableName = "blog";
static {
Configuration conf1 = new Configuration();
conf1.set("hbase.zookeeper.quorum", "server206,ap1,ap2");
conf1.set("hbase.zookeeper.property.clientPort", "2181");
conf = HBaseConfiguration.create(conf1);
}
/**
* @param args
* @throws Exception
*/
public static void main(String[] args) throws Exception {
// 列族
String[] familys = {"article", "author"};
// 创建表
try {
HBaseAdmin admin = new HBaseAdmin(conf);
if (admin.tableExists(tableName)) {
System.out.println("表已经存在,首先删除表");
admin.disableTable(tableName);
admin.deleteTable(tableName);
}
HTableDescriptor tableDesc = new HTableDescriptor(tableName);
for(int i=0; i<familys.length; i++){
HColumnDescriptor columnDescriptor = new HColumnDescriptor(familys[i]);
tableDesc.addFamily(columnDescriptor);
}
admin.createTable(tableDesc);
System.out.println("创建表成功");
} catch (Exception e) {
e.printStackTrace();
}
// 向表中插入数据
long time1 = System.currentTimeMillis();
System.out.println("开始向表中插入数据,当前时间为:" + time1);
for (int i=0; i<1; i++) {
InsertThread thread = new InsertThread(i * 1000000, 1000000, "thread" + i, time1);
thread.start();
}
}
public static class InsertThread extends Thread {
private int beginSite;
private int insertCount;
private String name;
private long beginTime;
public InsertThread(int beginSite, int insertCount, String name, long beginTime) {
this.beginSite = beginSite;
this.insertCount = insertCount;
this.name = name;
this.beginTime = beginTime;
}
@Override
public void run() {
HTable table = null;
try {
table = new HTable(conf, Bytes.toBytes(tableName));
table.setAutoFlush(false);
table.setWriteBufferSize(1 * 1024 * 1024);
} catch (IOException e1) {
e1.printStackTrace();
}
System.out.println("线程" + name + "从" + beginSite + "开始插入");
List<Put> putList = new ArrayList<Put>();
for (int i=beginSite; i<beginSite + insertCount; i++) {
Put put = new Put(Bytes.toBytes("" + i));
put.add(Bytes.toBytes("article"), Bytes.toBytes("tag"), Bytes.toBytes("hadoop"));
putList.add(put);
if (putList.size() > 10000) {
try {
table.put(putList);
table.flushCommits();
} catch (IOException e) {
e.printStackTrace();
}
putList.clear();
try {
Thread.sleep(5);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
try {
table.put(putList);
table.flushCommits();
table.close();
} catch (IOException e) {
System.out.println("线程" + name + "失败");
e.printStackTrace();
}
long currentTime = System.currentTimeMillis();
System.out.println("线程" + name + "结束,用时" + (currentTime - beginTime));
}
}
}
|
测试5次的结果分布图如下:
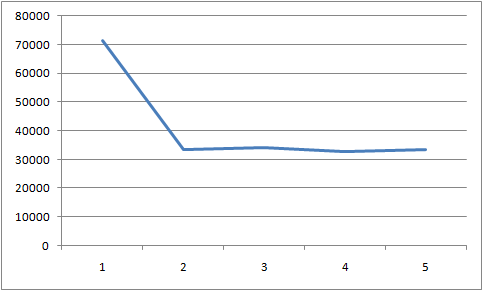
其中Y轴单位为毫秒。平均速度在1秒插入3万行记录。
10个线程每个线程插入10万行
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
| import java.io.IOException;
import java.util.ArrayList;
import java.util.List;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.HColumnDescriptor;
import org.apache.hadoop.hbase.HTableDescriptor;
import org.apache.hadoop.hbase.client.HBaseAdmin;
import org.apache.hadoop.hbase.client.HTable;
import org.apache.hadoop.hbase.client.Put;
import org.apache.hadoop.hbase.util.Bytes;
public class InsertRowThreadTest {
private static Configuration conf = null;
private static String tableName = "blog";
static {
Configuration conf1 = new Configuration();
conf1.set("hbase.zookeeper.quorum", "server206,ap1,ap2");
conf1.set("hbase.zookeeper.property.clientPort", "2181");
conf = HBaseConfiguration.create(conf1);
}
/**
* @param args
* @throws Exception
*/
public static void main(String[] args) throws Exception {
// 列族
String[] familys = {"article", "author"};
// 创建表
try {
HBaseAdmin admin = new HBaseAdmin(conf);
if (admin.tableExists(tableName)) {
System.out.println("表已经存在,首先删除表");
admin.disableTable(tableName);
admin.deleteTable(tableName);
}
HTableDescriptor tableDesc = new HTableDescriptor(tableName);
for(int i=0; i<familys.length; i++){
HColumnDescriptor columnDescriptor = new HColumnDescriptor(familys[i]);
tableDesc.addFamily(columnDescriptor);
}
admin.createTable(tableDesc);
System.out.println("创建表成功");
} catch (Exception e) {
e.printStackTrace();
}
// 向表中插入数据
long time1 = System.currentTimeMillis();
System.out.println("开始向表中插入数据,当前时间为:" + time1);
for (int i=0; i<10; i++) {
InsertThread thread = new InsertThread(i * 100000, 100000, "thread" + i, time1);
thread.start();
}
}
public static class InsertThread extends Thread {
private int beginSite;
private int insertCount;
private String name;
private long beginTime;
public InsertThread(int beginSite, int insertCount, String name, long beginTime) {
this.beginSite = beginSite;
this.insertCount = insertCount;
this.name = name;
this.beginTime = beginTime;
}
@Override
public void run() {
HTable table = null;
try {
table = new HTable(conf, Bytes.toBytes(tableName));
table.setAutoFlush(false);
table.setWriteBufferSize(1 * 1024 * 1024);
} catch (IOException e1) {
e1.printStackTrace();
}
System.out.println("线程" + name + "从" + beginSite + "开始插入");
List<Put> putList = new ArrayList<Put>();
for (int i=beginSite; i<beginSite + insertCount; i++) {
Put put = new Put(Bytes.toBytes("" + i));
put.add(Bytes.toBytes("article"), Bytes.toBytes("tag"), Bytes.toBytes("hadoop"));
putList.add(put);
if (putList.size() > 10000) {
try {
table.put(putList);
table.flushCommits();
} catch (IOException e) {
e.printStackTrace();
}
putList.clear();
try {
Thread.sleep(5);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
try {
table.put(putList);
table.flushCommits();
table.close();
} catch (IOException e) {
System.out.println("线程" + name + "失败");
e.printStackTrace();
}
long currentTime = System.currentTimeMillis();
System.out.println("线程" + name + "结束,用时" + (currentTime - beginTime));
}
}
}
|
耗时分布图为:
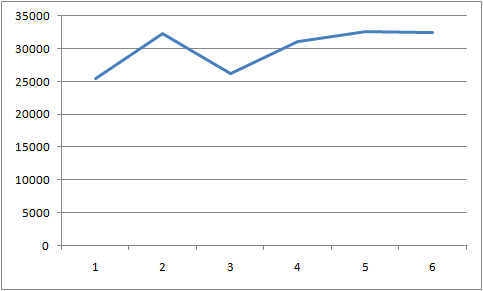
结果比单线程插入有提升。
20个线程每个线程插入5万行
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
| import java.io.IOException;
import java.util.ArrayList;
import java.util.List;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.HColumnDescriptor;
import org.apache.hadoop.hbase.HTableDescriptor;
import org.apache.hadoop.hbase.client.HBaseAdmin;
import org.apache.hadoop.hbase.client.HTable;
import org.apache.hadoop.hbase.client.Put;
import org.apache.hadoop.hbase.util.Bytes;
public class InsertRowThreadTest {
private static Configuration conf = null;
private static String tableName = "blog";
static {
Configuration conf1 = new Configuration();
conf1.set("hbase.zookeeper.quorum", "server206,ap1,ap2");
conf1.set("hbase.zookeeper.property.clientPort", "2181");
conf = HBaseConfiguration.create(conf1);
}
/**
* @param args
* @throws Exception
*/
public static void main(String[] args) throws Exception {
// 列族
String[] familys = {"article", "author"};
// 创建表
try {
HBaseAdmin admin = new HBaseAdmin(conf);
if (admin.tableExists(tableName)) {
System.out.println("表已经存在,首先删除表");
admin.disableTable(tableName);
admin.deleteTable(tableName);
}
HTableDescriptor tableDesc = new HTableDescriptor(tableName);
for(int i=0; i<familys.length; i++){
HColumnDescriptor columnDescriptor = new HColumnDescriptor(familys[i]);
tableDesc.addFamily(columnDescriptor);
}
admin.createTable(tableDesc);
System.out.println("创建表成功");
} catch (Exception e) {
e.printStackTrace();
}
// 向表中插入数据
long time1 = System.currentTimeMillis();
System.out.println("开始向表中插入数据,当前时间为:" + time1);
for (int i=0; i<20; i++) {
InsertThread thread = new InsertThread(i * 50000, 50000, "thread" + i, time1);
thread.start();
}
}
public static class InsertThread extends Thread {
private int beginSite;
private int insertCount;
private String name;
private long beginTime;
public InsertThread(int beginSite, int insertCount, String name, long beginTime) {
this.beginSite = beginSite;
this.insertCount = insertCount;
this.name = name;
this.beginTime = beginTime;
}
@Override
public void run() {
HTable table = null;
try {
table = new HTable(conf, Bytes.toBytes(tableName));
table.setAutoFlush(false);
table.setWriteBufferSize(1 * 1024 * 1024);
} catch (IOException e1) {
e1.printStackTrace();
}
System.out.println("线程" + name + "从" + beginSite + "开始插入");
List<Put> putList = new ArrayList<Put>();
for (int i=beginSite; i<beginSite + insertCount; i++) {
Put put = new Put(Bytes.toBytes("" + i));
put.add(Bytes.toBytes("article"), Bytes.toBytes("tag"), Bytes.toBytes("hadoop"));
putList.add(put);
if (putList.size() > 10000) {
try {
table.put(putList);
table.flushCommits();
} catch (IOException e) {
e.printStackTrace();
}
putList.clear();
try {
Thread.sleep(5);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
try {
table.put(putList);
table.flushCommits();
table.close();
} catch (IOException e) {
System.out.println("线程" + name + "失败");
e.printStackTrace();
}
long currentTime = System.currentTimeMillis();
System.out.println("线程" + name + "结束,用时" + (currentTime - beginTime));
}
}
}
|
结果如下:
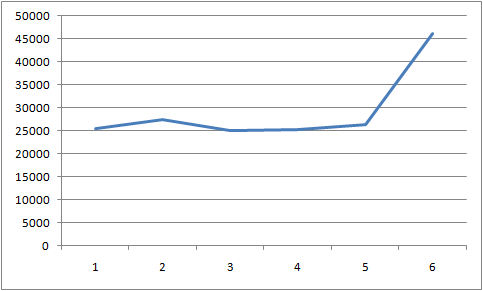
执行结果跟10个线程效果差不多。
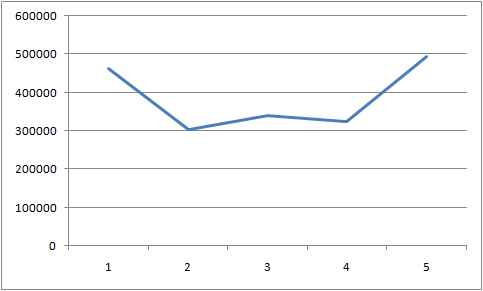
10个线程每个线程插入100万行
代码跟前面例子雷同,为节约篇幅未列出。
执行结果如下:
20个线程每个线程插入50万行
执行结果如下:
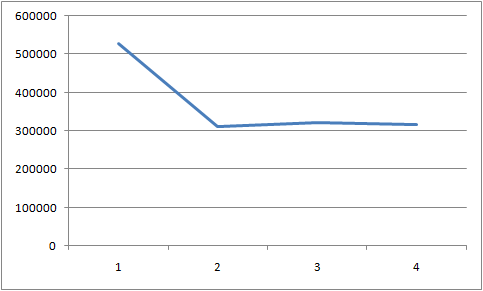
总结
- 多线程比单线程的插入效率有所提高,开10个线程与开20个线程的插入行效率差不多。
- 插入效率存在不稳定情况,通过折线图可以看出。
相关文章
在Linux上搭建Hadoop集群环境
在Linux上搭建HBase集群环境