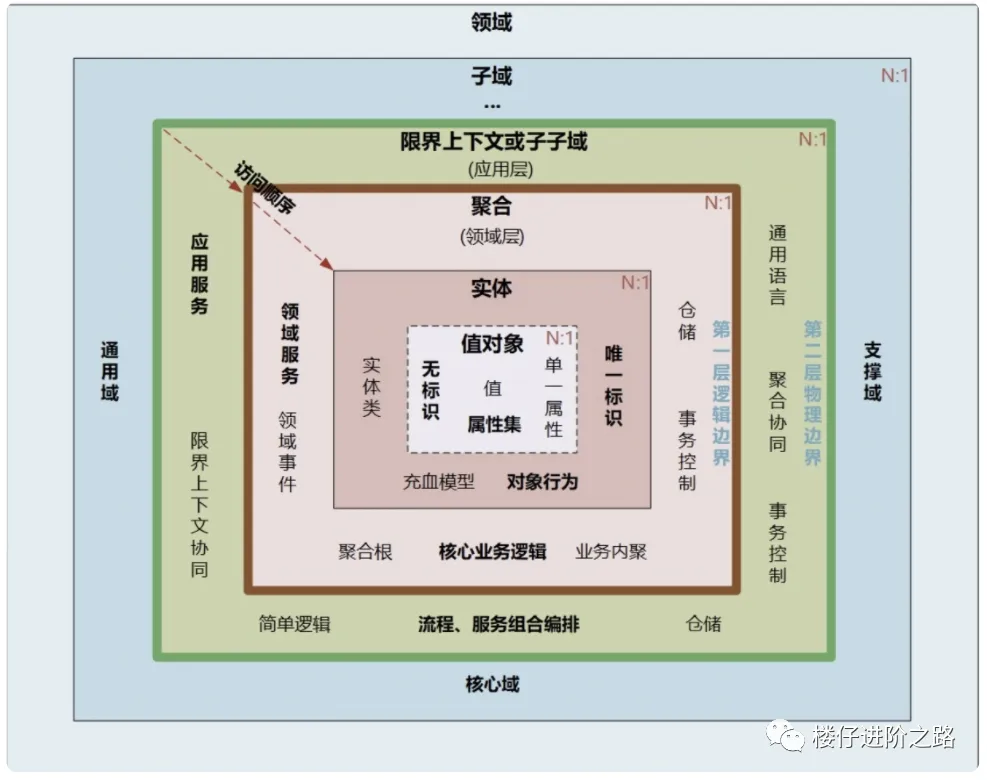
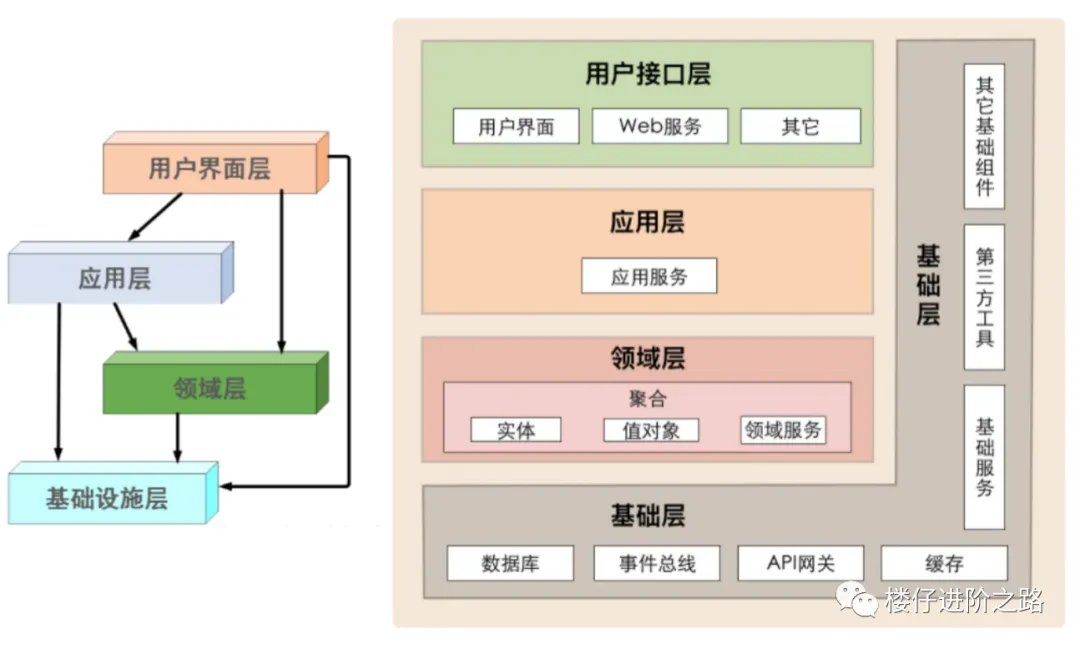
MVC 架构
1 MVC 结构
分为了 Model(模型层)、View(视图层)、Controller(控制器层)。
1.1 Model(模型层)
职责:表示应用程序的数据结构和业务逻辑。
包含内容:
- 数据实体类(如
User,Product) - 数据访问逻辑(如数据库 CRUD)
- 业务逻辑方法(如计算、状态切换)
1.2 View(视图层)
职责:负责数据的展示和用户界面。
包含内容:
- 页面模板(HTML / XML / JSX 等)
- UI 渲染逻辑
- 与用户交互(输入、按钮等)
1.3 Controller(控制器层)
职责:接收用户请求,调用模型处理数据,并选择视图进行展示。
包含内容:
- 路由逻辑
- 请求分发
- 控制流程协调(调用 Model → 返回给 View)
2 MVC 的交互流程(经典模式)
一个典型的用户请求处理流程如下:
- 用户交互: 用户在 View 上进行操作(例如,点击提交按钮)。
- 请求路由: View 将用户的输入/事件(例如,表单数据)传递给对应的 Controller(通常由框架的路由机制完成)。
- Controller 处理:
- Controller 解析用户输入。
- Controller 调用一个或多个 Model 对象的方法:
- 可能更新 Model 的状态(例如,将表单数据保存到数据库)。
- 可能从 Model 获取数据。
- Model 更新与通知:
- Model 执行业务逻辑,更新自身状态(可能涉及数据库操作等)。
- Model 通知所有注册的观察者(通常是依赖它的 View)状态已改变(这一步是观察者模式,在被动视图变体中可能由 Controller 显式通知)。
- View 更新:
- View 接收到 Model 状态改变的通知(或由 Controller 明确告知)。
- View 从 Model 查询最新的数据。
- View 使用新数据重新渲染用户界面。
- 用户看到更新: 用户看到更新后的 View。
3 MVC 的变体
3.1 更精细划分
为了更好地解耦和扩展,很多项目在经典 MVC 基础上再进一步划分层次,例如:
1 | ┌────────────────────┐ |