深度探索C++对象模型读书笔记_第二章:构造函数语义学
2.1 默认构造函数的生成
只有当编译器需要默认构造函数的时候才会合成默认构造函数,并不是类只要没有定义默认构造函数编译器就会合成默认构造函数,而是只有以下四种情况编译器会生成默认构造函数。编译器合成的默认构造函数仅会处理类的基类对象和类中的数据成员对象,对于类中的普通类型的非静态数据成员并不会作任何处理。比如类中一个指针类型的数据成员,编译器合成的默认构造函数不会对该指针作任何处理,该指针就是一个野指针。
带有默认构造函数的类成员对象
一个类没有定义任何构造函数,该类中包含了一个带有默认构造函数(包括了合成的默认构造函数和定义的默认构造函数)的类成员对象,那么编译器需要为此类合成一个默认构造函数,合成默认构造函数的时机为该构造函数被调用时。合成的默认构造函数默认为内联函数,如果不适合使用内联函数,就合成explicit static的构造函数。
默认构造函数、复制构造函数和赋值操作符的生成都是inline。inline函数有静态链接,不会被当前文件之外的文件看到。如果函数过于复杂不适合生成inline函数,会生成一个explicit non_inline static实体。
1 | class Dopey |
在上述例子中,foo()中需要调用Bashful的构造函数,编译器会为Bar类生成内联的默认构造函数。Bashful类会生成类似于下面的默认构造函数。
1 | inline Bar::Bar() |
默认构造函数的生成原则为:如果类A中包含了一个或一个以上的类成员对象,那么类A的默认构造函数必须调用每一个类成员的默认构造函数。但是不会初始化普通类型的变量,因此在上例中必须手动初始化mumble变量。在编译器合成的默认构造函数中类成员变量的默认构造函数的调用次序为成员变量在类中的声明顺序,该顺序和类成员的构造函数初始化列表顺序是一致的。
如果Snow_White类定义了如下的默认构造函数,则编译器会自动在定义的构造函数中增加调用类成员变量的代码,调用类成员变量相应构造函数的顺序仍然和类成员变量在类中的声明顺序一致。
从中可以看出类成员变量的构造函数的调用要早于类构造函数的调用,这一点是在很多面试题中经常会见到的。
1 | // 定义的默认构造函数,包含了类成员变量sneezy的初始化列表 |
带有默认构造函数的基类
在继承机制中,一个没有构造函数的子类继承自带有默认构造函数的基类,则子类的构造函数会被合成,并且会调用基类的默认构造函数。若子类没有定义默认构造函数,却定义了多个带参数的构造函数,编译器会扩张所有自定义的构造函数,将调用基类默认构造函数的代码添加到子类的构造函数的最前面。
从这里可以看出继承机制中,首先构造基类,后构造子类,这点也是面试题中经常遇到的。
带有虚函数的类
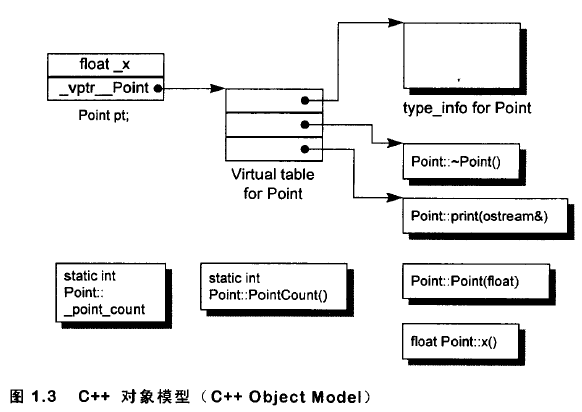
为了实现虚函数或虚继承机制,编译器需要为每一个类对象设定vptr(指向虚函数表的指针)的初始值,使其指向一个vtbl(虚函数表)的地址。如果类包含构造函数则编译器会生成一些代码来完成此工作;如果类没有任何构造函数,则编译器会在合成的默认构造函数中添加代码来完成此工作。
带有虚基类的类
需要维护内部指针来实现虚继承。
2.2 复制构造函数的生成
复制构造函数被调用有三种情况:
- 明确的一个对象的内容作为另外一个对象的初始值。如X xx = x或X xx(x)。
- 对象作为参数传递给函数时。
- 类对象作为函数返回值时。
合成复制构造函数的情况
如果一个类没有提供显式的复制构造函数,同默认构造函数一样,只有编译器认为需要合成复制构造函数时,编译器才会合成一个。那么问题来了,什么时候编译器才合成复制构造函数呢?书中给出的答案为当一个类不展现出_bitwise copy semantics_1的时候。具体来说有以下四种情况,跟类的默认构造函数的合成基本一致。
- 当类内包含一个类成员变量且类成员变量声明了复制构造函数。
- 当类继承的基类有复制构造函数(复制构造函数可以是显示声明或合成的)
- 一个类中包含了一个或多个虚函数
- 类继承自一个或多个虚基类
其中前面两种情况必须将成员变量或基类的复制构造函数的调用插入到合成的复制构造函数中,因此不是按照按比特复制的。第三和第四点分别用下面两小节来说明。
重新设定虚函数表的指针
当编译器需要在类对象中设定一个指向虚函数表的指针时,该类就不能再使用按位复制的复制构造函数了。
1 | class ZooAnimal |
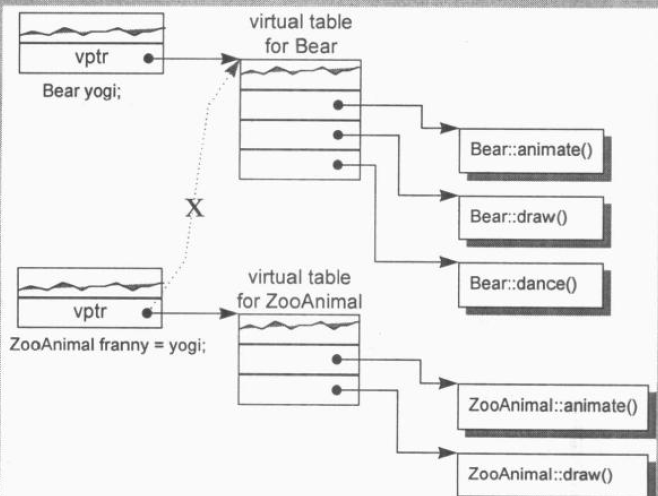
合成出来的ZooAnimal的复制构造函数会明确设定对象的vptr指向ZooAnimal的虚函数表,而不是从右值中复制过来的值。
处理virtual base class subobjects
虚基类的存在需要特别处理,一个类对象如果以另外一个类对象作为初始值,而后者有一个virtual base class subobjects,也会使按比特复制的复制构造函数失效。
每一个编译器都必须让派生的类对象的virtual base class subobjects位置在执行期准备完毕。按比特复制的复制构造函数可能会破坏virtual base class subobjects的位置,因此编译器必须在自己合成出来的复制构造函数中修改。
1 | class ZooAnimal |
文章的内容没有完全理解,虚继承机制使用较少,可以暂时不用理解。
2.3 程序转化语意学
本节涉及到了编译器优化的相关细节,由于较容易理解,可以直接看书上内容,对工作帮助不大。包括类对象的初始化优化,函数参数的初始化优化,函数返回值的初始化优化,使用者层面的优化和编译器层面的优化。
如果不是上节指定的四种情况,不需要显示的声明复制构造函数,因为显示的声明的复制构造函数往往效率不如编译器合成的复制构造函数效率高。编译器合成的复制构造函数利用memcpy()或memset()函数来合成,效率最高。
2.4 类成员的初始化列表
说到类成员的初始化列表必然想起一个经常出现的面试题:成员初始化列表的顺序是按照成员变量在类中声明的顺序。如果成员初始化列表的顺序和成员变量在类中声明的顺序不一致时某些编译器会提示警告。编译器将成员初始化列表的代码插入到构造函数的最开始位置,优先级跟调用类类型的成员变量的默认构造函数是一致的,都是跟类类型成员变量在类中的声明次序相关。
类成员初始化必须使用成员初始化列表的四种方式:
- 初始化一个引用类型的成员变量
- 初始化一个const的成员变量
- 调用基类的构造函数,且基类的构造函数采用成员初始化列表的方式
- 调用类成员的构造函数,且类成员的构造函数采用成员初始化列表的方式
1 | class Word |
此例子在构造函数中对成员变量进行测试,编译器对构造函数的扩张方式可能会生成如下的伪码:
1 | Word::Word() |
构造函数中生成了一个临时性的String对象,这浪费了一部分开销。如果将构造函数该成如下的定义方式:
1 | Word() : _name(0) |
即将其中的类成员变量更改为成员初始化列表的方式来初始化,编译器会自动将构造函数扩张为如下方式,这样减少了临时对象,提供了程序效率。
1 | Word::Word() |
引申
下面例子是对本章内容的一个简单概况,也是面试题中经常碰到的。
1 | class A |
上述代码执行的结果为:
1 | Base |
总结
本章讲述了合成的默认构造函数、合成的复制构造函数和构造函数的成员初始化列表。其中如果类没有定义默认构造函数,只有在文中提到的四种情况下编译器才会合成默认构造函数。合成的复制构造函数在需要的时候编译器就会生成,默认是按对象比特复制的方式实现,有四种情况下编译器是不按照比特复制的方式。
[1] bitwise copy semantics书中翻译为“位逐次拷贝”,就是按照内存中的字节进行复制类,感觉翻译不如不翻译好理解。