m Hash on the Layer 2 destination address of the rx packet. v Hash on the VLAN tag of the rx packet. t Hash on the Layer 3 protocol field of the rx packet. s Hash on the IP source address of the rx packet. d Hash on the IP destination address of the rx packet. f Hash on bytes 0 and 1 of the Layer 4 header of the rx packet. n Hash on bytes 2 and 3 of the Layer 4 header of the rx packet. r Discard all packets of this flow type. When this option is set, all other options are ignored.
修改完成后再查看网卡的 hash 策略如下:
1 2 3 4 5 6
$ ethtool -n eth0 rx-flow-hash udp4 UDP over IPV4 flows use these fields for computing Hash flow key: IP SA IP DA L4 bytes 0 & 1 [TCP/UDP src port] L4 bytes 2 & 3 [TCP/UDP dst port]
$ brctl showmacs br0 port no mac addr is local? ageing timer 1 02:50:89:59:ac:4b no 3.96 69 02:e2:14:78:d7:92 no 0.57 1 0a:1e:01:dc:67:87 no 10.23 1 0a:60:3c:ca:a8:85 no 6.04 1 0e:01:ce:d6:fc:66 no 8.36 1 0e:0c:f8:6c:08:75 no 56.73 58 0e:49:85:f6:a1:40 no 1.30 22 0e:c0:99:b0:d9:f9 no 0.85
File "/usr/lib64/python2.7/site-packages/jinja2/sandbox.py", line 22, in <module> from markupsafe import EscapeFormatter ImportError: cannot import name EscapeFormatter
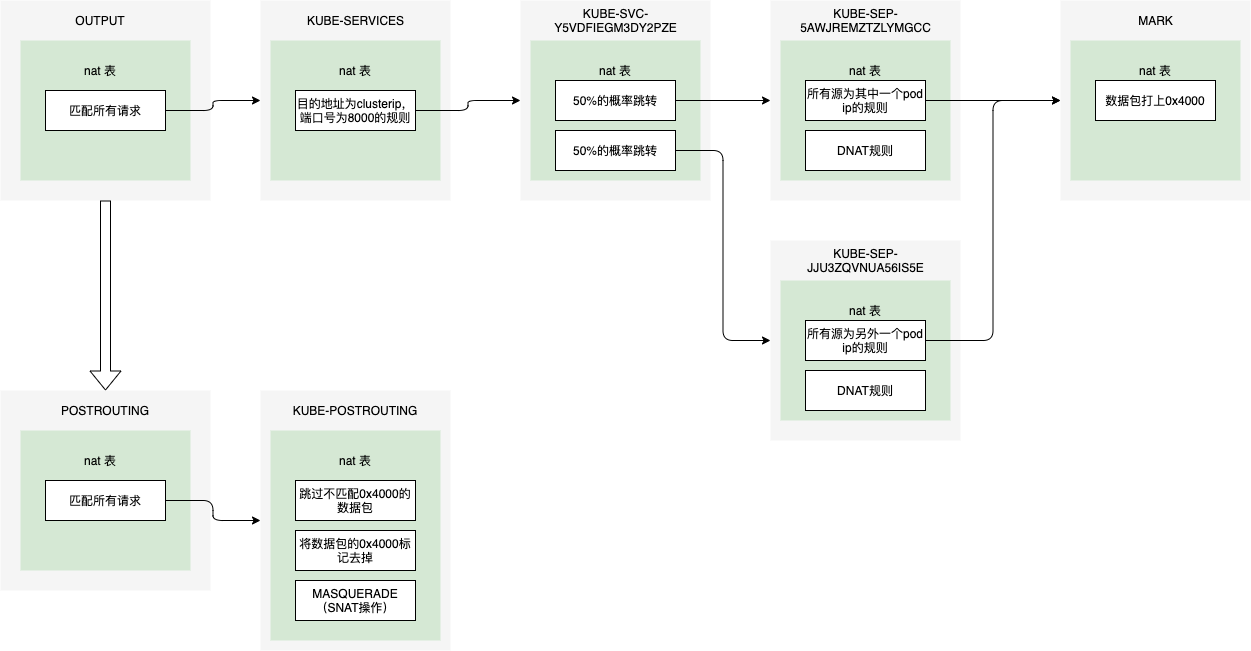
pkts bytes target prot opt in out source destination 349K 21M KUBE-SERVICES all -- * * 0.0.0.0/0 0.0.0.0/0 /* kubernetes service portals */
在KUBE-SERVICES链的最后一条规则为跳转到KUBE-NODEPORTS链
1
4079 246K KUBE-NODEPORTS all -- * * 0.0.0.0/0 0.0.0.0/0 /* kubernetes service nodeports; NOTE: this must be the last rule in this chain */ ADDRTYPE match dst-type LOCAL
# 10.149.112.0/23为pod网段 -A KUBE-XLB-76HLDRT5IPNSMPF5 -s 10.149.112.0/23 -m comment --comment "Redirect pods trying to reach external loadbalancer VIP to clusterIP" -j KUBE-SVC-76HLDRT5IPNSMPF5 -A KUBE-XLB-76HLDRT5IPNSMPF5 -m comment --comment "Balancing rule 0 for acs-system/nginx-ingress-lb-cloudbiz:http" -j KUBE-SEP-XZXLBWOKJBSJBGVU
-A KUBE-SVC-76HLDRT5IPNSMPF5 -m statistic --mode random --probability 0.50000000000 -j KUBE-SEP-XZXLBWOKJBSJBGVU -A KUBE-SVC-76HLDRT5IPNSMPF5 -j KUBE-SEP-GP4UCOZEF3X7PGLR
-A KUBE-SEP-XZXLBWOKJBSJBGVU -s 10.149.112.45/32 -j KUBE-MARK-MASQ -A KUBE-SEP-XZXLBWOKJBSJBGVU -p tcp -m tcp -j DNAT --to-destination 10.149.112.45:80 -A KUBE-SEP-GP4UCOZEF3X7PGLR -s 10.149.112.46/32 -j KUBE-MARK-MASQ -A KUBE-SEP-GP4UCOZEF3X7PGLR -p tcp -m tcp -j DNAT --to-destination 10.149.112.46:80