简介 华为云开源的多云容器编排项目,目前为CNCF沙箱项目。Karmada是基于kubefed v2 进行修改的一个项目,因此里面很多概念都是取自kubefed v2。
Karmada相对于kubefed v2的最大优点:完全兼容k8s的API 。karmada提供了一个一套独立的karmada-apiserver,跟kube-apiserver是兼容的,使用方在调用的时候只需要访问karmada-apiserver就可以了。
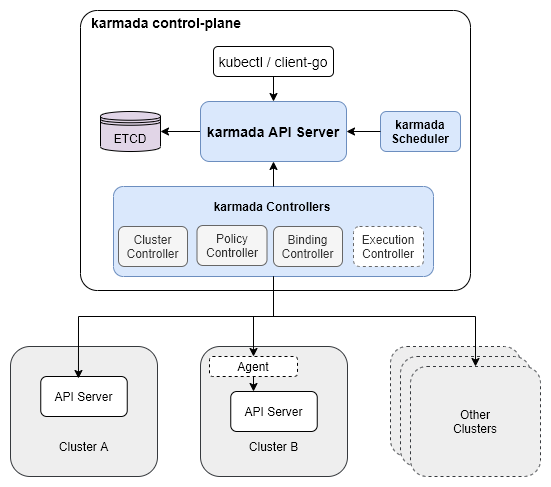
架构
karmada api server,用来给其他的组件提供rest api
karmada controller manager
karmada scheduler
karmada会新建一个ETCD,用来存储karmada的API对象。
karmada controller manager内部包含了多个controller的功能,会通过karmada apiserver来watch karmada对象,并通过调用各个子集群的apiserver来创建标准的k8s对象,包含了如下的controller对象:
Cluster Controller:用来管理子集群的声明周期
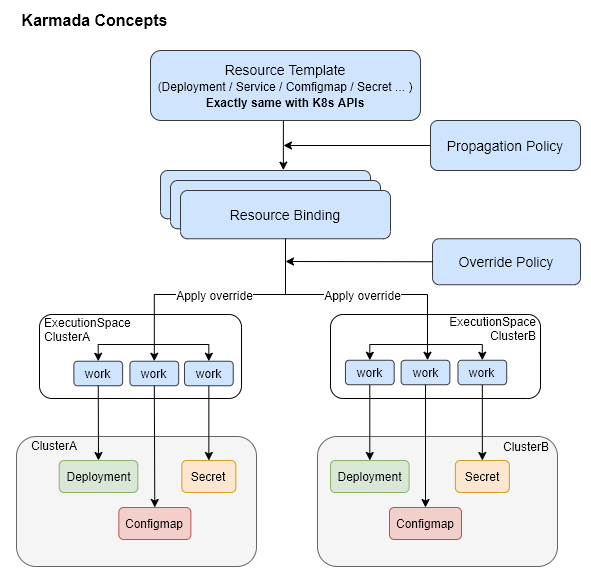
Policy Controller:监听PropagationPolicy对象,通过resourceSelector找到匹配中的资源,并创建ResourceBinding对象。
Binding Controller:监听ResourceBinding对象,并创建每个集群的Work对象。
Execution Controller:监听Work对象,一旦Work对象场景后,会在子集群中创建Work关联的k8s对象。
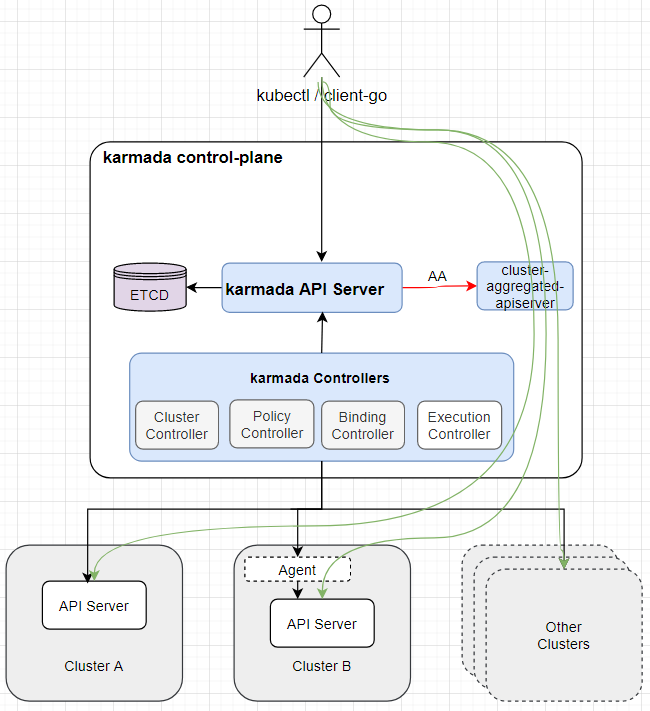
组件 karmada-aggregated-apiserver 在karmada-apiserver上注册的api信息
etcd 用来存放karmada的元数据信息
CRD Cluster 需要使用kamada-apiserver来查询
unfold me to see the yaml
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 apiVersion: cluster.karmada.io/v1alpha1 kind: Cluster metadata: finalizers: - karmada.io/cluster-controller name: member1 spec: apiEndpoint: https://172.18.0.3:6443 impersonatorSecretRef: name: member1-impersonator namespace: karmada-cluster secretRef: name: member1 namespace: karmada-cluster syncMode: Push status: apiEnablements: - groupVersion: admissionregistration.k8s.io/v1 resources: - kind: MutatingWebhookConfiguration name: mutatingwebhookconfigurations - kind: ValidatingWebhookConfiguration name: validatingwebhookconfigurations - groupVersion: apiextensions.k8s.io/v1 resources: - kind: CustomResourceDefinition name: customresourcedefinitions - groupVersion: apiregistration.k8s.io/v1 resources: - kind: APIService name: apiservices - groupVersion: apps/v1 resources: - kind: ControllerRevision name: controllerrevisions - kind: DaemonSet name: daemonsets - kind: Deployment name: deployments - kind: ReplicaSet name: replicasets - kind: StatefulSet name: statefulsets - groupVersion: authentication.k8s.io/v1 resources: - kind: TokenReview name: tokenreviews - groupVersion: authorization.k8s.io/v1 resources: - kind: LocalSubjectAccessReview name: localsubjectaccessreviews - kind: SelfSubjectAccessReview name: selfsubjectaccessreviews - kind: SelfSubjectRulesReview name: selfsubjectrulesreviews - kind: SubjectAccessReview name: subjectaccessreviews - groupVersion: autoscaling/v1 resources: - kind: HorizontalPodAutoscaler name: horizontalpodautoscalers - groupVersion: autoscaling/v2beta1 resources: - kind: HorizontalPodAutoscaler name: horizontalpodautoscalers - groupVersion: autoscaling/v2beta2 resources: - kind: HorizontalPodAutoscaler name: horizontalpodautoscalers - groupVersion: batch/v1 resources: - kind: CronJob name: cronjobs - kind: Job name: jobs - groupVersion: batch/v1beta1 resources: - kind: CronJob name: cronjobs - groupVersion: certificates.k8s.io/v1 resources: - kind: CertificateSigningRequest name: certificatesigningrequests - groupVersion: coordination.k8s.io/v1 resources: - kind: Lease name: leases - groupVersion: discovery.k8s.io/v1 resources: - kind: EndpointSlice name: endpointslices - groupVersion: discovery.k8s.io/v1beta1 resources: - kind: EndpointSlice name: endpointslices - groupVersion: events.k8s.io/v1 resources: - kind: Event name: events - groupVersion: events.k8s.io/v1beta1 resources: - kind: Event name: events - groupVersion: flowcontrol.apiserver.k8s.io/v1beta1 resources: - kind: FlowSchema name: flowschemas - kind: PriorityLevelConfiguration name: prioritylevelconfigurations - groupVersion: networking.k8s.io/v1 resources: - kind: IngressClass name: ingressclasses - kind: Ingress name: ingresses - kind: NetworkPolicy name: networkpolicies - groupVersion: node.k8s.io/v1 resources: - kind: RuntimeClass name: runtimeclasses - groupVersion: node.k8s.io/v1beta1 resources: - kind: RuntimeClass name: runtimeclasses - groupVersion: policy/v1 resources: - kind: PodDisruptionBudget name: poddisruptionbudgets - groupVersion: policy/v1beta1 resources: - kind: PodDisruptionBudget name: poddisruptionbudgets - kind: PodSecurityPolicy name: podsecuritypolicies - groupVersion: rbac.authorization.k8s.io/v1 resources: - kind: ClusterRoleBinding name: clusterrolebindings - kind: ClusterRole name: clusterroles - kind: RoleBinding name: rolebindings - kind: Role name: roles - groupVersion: scheduling.k8s.io/v1 resources: - kind: PriorityClass name: priorityclasses - groupVersion: storage.k8s.io/v1 resources: - kind: CSIDriver name: csidrivers - kind: CSINode name: csinodes - kind: StorageClass name: storageclasses - kind: VolumeAttachment name: volumeattachments - groupVersion: storage.k8s.io/v1beta1 resources: - kind: CSIStorageCapacity name: csistoragecapacities - groupVersion: v1 resources: - kind: Binding name: bindings - kind: ComponentStatus name: componentstatuses - kind: ConfigMap name: configmaps - kind: Endpoints name: endpoints - kind: Event name: events - kind: LimitRange name: limitranges - kind: Namespace name: namespaces - kind: Node name: nodes - kind: PersistentVolumeClaim name: persistentvolumeclaims - kind: PersistentVolume name: persistentvolumes - kind: Pod name: pods - kind: PodTemplate name: podtemplates - kind: ReplicationController name: replicationcontrollers - kind: ResourceQuota name: resourcequotas - kind: Secret name: secrets - kind: ServiceAccount name: serviceaccounts - kind: Service name: services conditions: - lastTransitionTime: "2022-02-21T08:27:56Z" message: cluster is healthy and ready to accept workloads reason: ClusterReady status: "True" type: Ready kubernetesVersion: v1.22.0 nodeSummary: readyNum: 1 totalNum: 1 resourceSummary: allocatable: cpu: "8" ephemeral-storage: 41152812Ki hugepages-1Gi: "0" hugepages-2Mi: "0" memory: 32192720Ki pods: "110" allocated: cpu: 950m memory: 290Mi pods: "9"
PropagationPolicy 应用发布策略
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 apiVersion: policy.karmada.io/v1alpha1 kind: PropagationPolicy metadata: name: nginx-propagation namespace: default spec: placement: clusterAffinity: clusterNames: - member1 - member2 replicaScheduling: replicaDivisionPreference: Weighted· replicaSchedulingType: Divided weightPreference: staticWeightList: - targetCluster: clusterNames: - member1 weight: 1 - targetCluster: clusterNames: - member2 weight: 1 resourceSelectors: - apiVersion: apps/v1 kind: Deployment name: nginx namespace: default
ClusterPropagationPolicy 用来定义Cluster级别资源的发布策略
1 2 3 4 5 6 7 8 9 10 11 12 13 14 apiVersion: policy.karmada.io/v1alpha1 kind: ClusterPropagationPolicy metadata: name: serviceexport-policy spec: resourceSelectors: - apiVersion: apiextensions.k8s.io/v1 kind: CustomResourceDefinition name: serviceexports.multicluster.x-k8s.io placement: clusterAffinity: clusterNames: - member1 - member2
OverridePolicy 用于修改不同集群内的对象
1 2 3 4 5 6 7 8 9 10 11 12 apiVersion: policy.karmada.io/v1alpha1 kind: OverridePolicy metadata: name: example spec: ... overriders: commandOverrider: - containerName: myapp operator: remove value: - --parameter1=foo
安装 karmada提供了三种安装方式:
kubectl karmada插件的方式安装,较新的特性,v1.0版本才会提供,当前最新版本为v0.10.1
helm chart方式安装
使用源码安装
安装kubectl插件 karmada提供了一个cli的工具,可以是单独的二进制工具kubectl-karmada,也可以是kubectl的插件karmada,本文以kubectl插件的方式进行安装。
1 kubectl krew install karmada
接下来就可以执行 kubectl karmada命令了。
helm chart的方式安装 使用kind插件一个k8s集群 host,此处步骤略
在源码目录下执行如下的命令
1 helm install karmada -n karmada-system --create-namespace ./charts
会在karmada-system下部署如下管控的组件
1 2 3 4 5 6 7 8 9 10 11 $ kubectl get deployments -n karmada-system NAME READY UP-TO-DATE AVAILABLE AGE karmada-apiserver 1 /1 1 1 83 s karmada-controller-manager 1 /1 1 1 83 s karmada-kube-controller-manager 1 /1 1 1 83 s karmada-scheduler 1 /1 1 1 83 s karmada-webhook 1 /1 1 1 83 s $ kubectl get statefulsets -n karmada-system NAME READY AGE etcd 1 /1 2 m1s
从源码安装一个本地测试集群 本方式仅用于本地测试,会自动使用kind拉起测试的k8s集群,包括了一个host集群和3个member集群。
执行如下命令,会执行如下的任务:
使用kind启动一个新的k8s集群host
构建karmada的控制平面,并部署控制平面到host集群
创建3个member集群并加入到karmada中1 2 3 git clone https://github.com/karmada-io /karmada cd karmadahack/local-up-karmada .sh
https://github.com/karmada-io/karmada/blob/master/hack/util.sh#L375 https://127.0.0.1:45195 这样的本地随机端口,只能在宿主机网络中访问。如果要想在两个k8s集群之间访问是不可行的。脚本中使用kubectl config set-cluster 命令将集群apiserver的地址替换为了docker网段的ip地址,以便于多个k8s集群之间的互访。https://github.com/karmada-io/karmada/blob/master/hack/util.sh#L389
可以看到创建了如下的4个k8s cluster
1 2 3 4 5 $ kind get clusterskarmada-host member1 member2 member3
但这四个集群会分为两个kubeconfig文件 ~/.kube/karmada.config 和 ~/.kube/members.config。karmada又分为了两个context karmada-apiserver和karmada-host,两者连接同一个k8s集群。karmada-apiserver为跟karmada控制平台交互使用的context,为容器中的karmada-apiserver。karmada-host连接容器的kube-apiserver。
如果要连接host集群设置环境变量:export KUBECONFIG=”$HOME/.kube/karmada.config”
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 $ export KUBECONFIG="$HOME/.kube/karmada.config" $ kctx karmada-host $ k get deploy -n karmada-system NAME READY UP-TO-DATE AVAILABLE AGE karmada-aggregated-apiserver 2 /2 2 2 17m karmada-apiserver 1 /1 1 1 18m karmada-controller-manager 2 /2 2 2 17m karmada-kube-controller-manager 1 /1 1 1 17m karmada-scheduler 2 /2 2 2 17m karmada-scheduler-estimator-member1 2 /2 2 2 17m karmada-scheduler-estimator-member2 2 /2 2 2 17m karmada-scheduler-estimator-member3 2 /2 2 2 17m karmada-webhook 2 /2 2 2 17m
在host集群中可以看到会创建出如下的pod
1 2 3 4 5 6 7 8 9 10 11 12 NAME READY STATUS RESTARTS AGE etcd-0 1 /1 Running 0 18 h karmada-aggregated-apiserver-7b88b8df99-95twq 1 /1 Running 0 18 h karmada-apiserver-5746cf97bb-pspfg 1 /1 Running 0 18 h karmada-controller-manager-7d66968445-h4xsc 1 /1 Running 0 18 h karmada-kube-controller-manager-869d9df85-f4bqj 1 /1 Running 0 18 h karmada-scheduler-8677cdf96d-psnlw 1 /1 Running 0 18 h karmada-scheduler-estimator-member1-696b54fd56-jjg6b 1 /1 Running 0 18 h karmada-scheduler-estimator-member2-774fb84c5d-fldhd 1 /1 Running 0 18 h karmada-scheduler-estimator-member3-5c7d87f4b4-fk4lj 1 /1 Running 0 18 h karmada-webhook-79b87f7c5f-lt8ps 1 /1 Running 0 18 h
在karmada-apiserver集群会创建出如下的Cluster,同时可以看到有两个Push模式一个Pull模式的集群。
1 2 3 4 5 6 7 $ kctx karmada-apiserver Switched to context "karmada-apiserver" . $ kubectl get clusters NAME VERSION MODE READY AGE member1 v1.22.0 Push True 61m member2 v1.22.0 Push True 61m member3 v1.22.0 Pull True 61m
应用发布
将context切换到karmada-host,在host集群部署应用nginx
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 $ export KUBECONFIG="$HOME /.kube/karmada.config" $ kctx karmada-apiserver $ kubectl create -f samples/nginx/propagationpolicy.yaml$ cat samples/nginx/propagationpolicy.yamlapiVersion: policy.karmada.io/v1alpha1 kind: PropagationPolicy metadata: name: nginx-propagation spec: resourceSelectors: - apiVersion: apps/v1 kind: Deployment name: nginx placement: clusterAffinity: clusterNames: - member1 - member2 replicaScheduling: replicaDivisionPreference: Weighted replicaSchedulingType: Divided weightPreference: staticWeightList: - targetCluster: clusterNames: - member1 weight: 1 - targetCluster: clusterNames: - member2 weight: 1
在karmada-apiserver中提交deployment。deployment提交后实际上仅为一个模板,只有PropagationPolicy跟deployment关联后,才会真正部署。deployment中指定的副本数为所有子集群的副本数综合。
1 2 3 4 5 6 7 $ kubectl create -f samples/nginx/deployment.yaml $ k get deploy NAME READY UP-TO-DATE AVAILABLE AGE nginx 2 /2 2 2 7m37s $ k get pod No resources found in default namespace.
通过karmadactl命令可以查询环境中的所有子集群的pod状态
1 2 3 4 5 6 $ karmadactl get pod The karmadactl get command now only supports Push mode, [ member3 ] are not push mode NAME CLUSTER READY STATUS RESTARTS AGE nginx-6799fc88d8-4w2gc member1 1 /1 Running 0 4m16s nginx-6799fc88d8-j77f5 member2 1 /1 Running 0 4m16s
元集群访问子集群
可以看到在karmada-apiserver上注册了AA服务,group为cluster.karmada.io
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 apiVersion: apiregistration.k8s.io/v1 kind: APIService metadata: labels: apiserver: "true" app: karmada-aggregated-apiserver name: v1alpha1.cluster.karmada.io spec: group: cluster.karmada.io groupPriorityMinimum: 2000 insecureSkipTLSVerify: true service: name: karmada-aggregated-apiserver namespace: karmada-system port: 443 version: v1alpha1 versionPriority: 10 status: conditions: - lastTransitionTime: "2022-02-21T08:27:47Z" message: all checks passed reason: Passed status: "True" type: Available
如果直接使用kubectl访问karmada-apiserver服务,会提示存在权限问题
1 2 ¥ kubectl --kubeconfig ~/.kube/karmada-apiserver.config --context karmada-apiserver get --raw /apis/cluster.karmada.io/v1alpha1/clusters/member1/proxy/api/v1/nodes Error from server (Forbidden): users "system:admin" is forbidden: User "system:serviceaccount:karmada-cluster:karmada-impersonator" cannot impersonate resource "users" in API group "" at the cluster scope
给karmada-apiserver的Account system:admin授权,创建文件cluster-proxy-rbac.yaml,内容如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 apiVersion: rbac.authorization.k8s.io/v1 kind: ClusterRole metadata: name: cluster-proxy-clusterrole rules: - apiGroups: - 'cluster.karmada.io' resources: - clusters/proxy resourceNames: - member1 - member2 - member3 verbs: - '*' --- apiVersion: rbac.authorization.k8s.io/v1 kind: ClusterRoleBinding metadata: name: cluster-proxy-clusterrolebinding roleRef: apiGroup: rbac.authorization.k8s.io kind: ClusterRole name: cluster-proxy-clusterrole subjects: - kind: User name: "system:admin"
执行如下命令即可给karmada-apiserver的Account system:admin 授权可访问AA服务的member1-3
1 kubectl --kubeconfig /root/.kube/karmada.config --context karmada-apiserver apply -f cluster-proxy-rbac.yaml
通过url的形式访问AA服务,返回数据格式为json
1 kubectl --kubeconfig ~/.kube/karmada-apiserver.config --context karmada-apiserver get --raw /apis/cluster.karmada.io/v1alpha1/clusters/member1/proxy/api/v1/nodes
如果要想使用 kubectl get node 的形式来访问,则需要在kubeconfig文件中server字段的url地址后追加url /apis/cluster.karmada.io/v1alpha1/clusters/{clustername}/proxy
给特定的账号授权 在karmada-apiserver中创建账号 tom
1 kubectl --kubeconfig /root/.kube/karmada.config --context karmada-apiserver create serviceaccount tom
在karmada-apiserver中提交如下的yaml文件,用来给tom账号增加访问member1集群的权限
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 apiVersion: rbac.authorization.k8s.io/v1 kind: ClusterRole metadata: name: cluster-proxy-clusterrole rules: - apiGroups: - 'cluster.karmada.io' resources: - clusters/proxy resourceNames: - member1 verbs: - '*' --- apiVersion: rbac.authorization.k8s.io/v1 kind: ClusterRoleBinding metadata: name: cluster-proxy-clusterrolebinding roleRef: apiGroup: rbac.authorization.k8s.io kind: ClusterRole name: cluster-proxy-clusterrole subjects: - kind: ServiceAccount name: tom namespace: default - kind: Group name: "system:serviceaccounts" - kind: Group name: "system:serviceaccounts:default"
执行如下命令提交
1 kubectl --kubeconfig /root/.kube/karmada.config --context karmada-apiserver apply -f cluster-proxy-rbac.yaml
获取karmada-apiserver集群的tom账号的token信息
1 kubectl --kubeconfig /root/.kube/karmada.config --context karmada-apiserver get secret `kubectl --kubeconfig /root/.kube/karmada.config --context karmada-apiserver get sa tom -oyaml | grep token | awk '{print $3}' ` -oyaml | grep token: | awk '{print $2}' | base64 -d
创建~/.kube/tom.config文件,其中token信息为上一步获取的token,server的地址可以查看 ~/.kube/karmada-apiserver.config文件
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 apiVersion: v1 clusters: - cluster: insecure-skip-tls-verify: true server: {karmada-apiserver-address } name: tom contexts: - context: cluster: tom user: tom name: tom current-context: tom kind: Config users: - name: tom user: token: {token }
通过karmada-apiserver的tom用户访问member1集群
1 2 3 4 5 6 $ kubectl --kubeconfig ~/.kube/tom.config get --raw /apis/cluster.karmada.io/v1alpha1/clusters/member1/proxy/apis $ kubectl --kubeconfig ~/.kube/tom.config get --raw /apis/cluster.karmada.io/v1alpha1/clusters/member1/proxy/api/v1/nodes Error from server (Forbidden): nodes is forbidden: User "system:serviceaccount:default:tom" cannot list resource "nodes" in API group "" at the cluster scope
在member1集群将tom账号绑定权限,创建member1-rbac.yaml文件,内容如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 apiVersion: rbac.authorization.k8s.io/v1 kind: ClusterRole metadata: name: tom rules: - apiGroups: - '*' resources: - '*' verbs: - '*' --- apiVersion: rbac.authorization.k8s.io/v1 kind: ClusterRoleBinding metadata: name: tom roleRef: apiGroup: rbac.authorization.k8s.io kind: ClusterRole name: tom subjects: - kind: ServiceAccount name: tom namespace: default
权限在member1集群生效
1 kubectl --kubeconfig /root/.kube/members.config --context member1 apply -f member1-rbac.yaml
重新执行命令即可以访问子集群中的数据
1 kubectl --kubeconfig ~/.kube/tom.config get --raw /apis/cluster.karmada.io/v1alpha1/clusters/member1/proxy/api/v1/nodes
集群注册 支持Push和Pull两种模式。
push模式karmada会直接访问成员集群的kuba-apiserver。
pull模式针对的场景是中心集群无法直接子集群的场景。每个子集群运行karmada-agent组件,一旦karmada-agent部署完成后就会自动向host集群注册,karmada-agent会watch host集群的karmada-es-下的cr,并在本集群部署。





](https://kuring.oss-cn-beijing.aliyuncs.com/common/kube-eventer.png)
